对于某些人来说,这可能是一个非常基本的问题。我试图了解strcpy在幕后的实际效果。例如,在此代码中
#include <stdio.h>
#include <string.h>
int main ()
{
char s[6] = "Hello";
char a[20] = "world isnsadsdas";
strcpy(s,a);
printf("%s\n",s);
printf("%d\n", sizeof(s));
return 0;
}
当我宣布s是一个大小小于源的静态数组时。我认为它不打印整个单词,但它确实打印world isnsadsdas ..所以,我认为如果目标小于源,这个strcpy函数可能会分配新的大小。但是现在,当我检查sizeof(s)时,它仍然是6,但它的打印输出不止于此。实际工作怎么样?
答案 0 :(得分:12)
您刚刚导致了未定义的行为,因此任何事情都可能发生。在你的情况下,你很幸运,并没有崩溃,但你不应该依赖于这种情况。这是一个简化的strcpy实现(但它与许多真实的实现并不太远):
char *strcpy(char *d, const char *s)
{
char *saved = d;
while (*s)
{
*d++ = *s++;
}
*d = 0;
return saved;
}
sizeof只是从编译时返回数组的大小。如果您使用strlen,我认为您会看到您的期望。但正如我上面提到的,依赖未定义的行为是一个坏主意。
答案 1 :(得分:3)
http://natashenka.ca/wp-content/uploads/2014/01/strcpy8x11.png
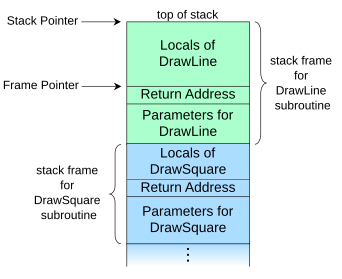
由于您正在展示的原因,strcpy被认为是危险的。您创建的两个缓冲区是存储在函数堆栈框架中的局部变量。这大致是堆栈框架的样子: http://upload.wikimedia.org/wikipedia/commons/thumb/d/d3/Call_stack_layout.svg/342px-Call_stack_layout.svg.pngFYI事物被置于堆栈顶部意味着它通过内存向后增长(这并不意味着内存中的变量被向后读取,只是新的变量被放在“旧的”后面)。这意味着如果你在函数的堆栈框架的locals部分写得足够远,你将在复制到的变量之后向其他每个堆栈变量写入并突破到其他部分,并最终覆盖返回指针。结果是,如果你聪明,你可以完全控制函数返回的位置。你可以让它做任何事情,但不是你担心的问题。
如你所知,通过使第一个缓冲区为6个字符长的5个字符串,C字符串以空字节结尾\ x00。 strcpy函数复制字节直到源字节为0,但它不检查目标是否长,这就是它可以复制数组边界的原因。这也是您的打印正在读取超过其大小的缓冲区的原因,它读取到\ x00。有趣的是,strcpy可能已写入s的数据,具体取决于编译器在堆栈中给出的顺序,所以一个有趣的练习可能是打印a并看看你是否得到类似'snsadsdas'的东西,但我不能确保即使是污染s也会是什么样子,因为由于各种原因,堆栈条目之间有时会出现字节。)
如果这个缓冲区有一个密码,用于检查带有散列函数的代码,并将它从任何地方复制到堆栈中的缓冲区(如果服务器或文本框等,则为网络数据包)你可以很好地复制来自源的数据,而不是目标缓冲区可以容纳的数据,并将程序的返回控制权交给任何能够向你发送数据包或尝试密码的用户。他们只需要输入正确数量的字符,然后输入正确的字符来表示ram中某个地址的地址即可跳转到。
如果检查边界并且可能修剪源字符串,则可以使用strcpy,但这被认为是不好的做法。还有更多现代函数采用最大长度,如http://www.cplusplus.com/reference/cstring/strncpy/
哦,最后,这称为缓冲区溢出。一些编译器在每个堆栈条目之前和之后添加一个由OS随机选择的一小块字节。在每次复制之后,OS会根据其副本检查这些字节,如果它们不同则终止程序。这解决了很多安全问题,但仍然可以将字节复制到堆栈中以覆盖函数的指针,以处理在更改这些字节时发生的情况,从而让您执行相同的操作。做正确的事情变得更加困难。
答案 2 :(得分:2)
在C中没有对数组进行边界检查,为了获得更好的性能,可能会有更大的性能,并且可能会让自己陷入困境。
strcpy()并不关心目标缓冲区是否足够大,因此复制太多字节会导致未定义的行为。
这是引入新版strcpy的原因之一,您可以在其中指定目标缓冲区大小strcpy_s()
答案 3 :(得分:1)
您依赖于未定义的行为,因为编译器已选择将两个数组放置在代码恰好工作的位置。这可能在将来不起作用。
对于sizeof运算符,这在编译时计算出来。
使用足够的数组大小后,需要使用strlen来获取字符串的长度。
答案 4 :(得分:1)
请注意,sizeof(s)是在运行时确定的。使用strlen()查找占用的字符数。当你执行strcpy()源字符串将被目标字符串替换,所以你的输出不会是“Helloworld isnsadsdas”
#include <stdio.h>
#include <string.h>
main ()
{
char s[6] = "Hello";
char a[20] = "world isnsadsdas";
strcpy(s,a);
printf("%s\n",s);
printf("%d\n", strlen(s));
}
答案 5 :(得分:0)
了解strcpy幕后工作原理的最佳方法是...阅读源代码! 您可以阅读GLibC的来源:http://fossies.org/dox/glibc-2.17/strcpy_8c_source.html。我希望它有所帮助!
答案 6 :(得分:0)
更好的解决方案是
char *strcpy(char *p,char const *q)
{
char *saved=p;
while(*p++=*q++);//enter code here
return saved;
}
答案 7 :(得分:0)
在每个字符串/字符数组的末尾都有一个null terminator character '\0',它标记了字符串/字符数组的结尾。
strcpy()执行其任务,直到它看到'\ 0'字符。
printf()也会预先确定其任务,直到看到'\ 0'字符。
sizeof() 不 对数组的内容感兴趣,只有它的分配大小(它应该有多大),因此没有考虑字符串/字符数组实际结束的位置(实际有多大)。
与sizeof()相反,有strlen() 对字符串实际存在的时间感兴趣(不知道它应该是多长时间) )因此计算字符数,直到它到达结尾('\ 0'字符)停止(它不包括'\ 0'字符)。
{kind=link}
{kind=link}