在Java中增长数组的大多数内存有效方法?
我不太关心时间效率(操作很少),而是关于内存效率:我可以在不暂时拥有所有值的情况下增长数组吗?
是否有更有效的方法来扩展大型阵列而不是创建新阵列并复制所有值?比如,用一个新的连接它?
将固定大小的数组存储在另一个数组中并重新分配/复制那个顶级数组怎么样?这会留下实际价值吗?
我知道ArrayList,但是我需要很多关于访问数组的控制,并且访问需要非常快。例如,我认为我更喜欢a[i]到al.get(i)。
我关心这个的主要原因是所讨论的数组(或许多这样的数组)可能很好地占据主内存的足够大部分,这是在丢弃原始文件之前创建双倍大小的副本的通常策略可能无法解决。这可能意味着我需要重新考虑整体战略(或我的硬件建议)。
12 个答案:
答案 0 :(得分:29)
动态调整大小“数组”或项列表的最佳方法是使用ArrayList。
Java已经在这个数据结构中内置了非常有效的大小调整算法。
但是,如果您必须调整自己的数组,最好使用System.arraycopy()或Arrays.copyOf()。
Arrays.copyOf()可以最简单地使用:
int[] oldArr;
int newArr = Arrays.copyOf(oldArr, oldArr.length * 2);
这将为您提供一个与旧数组具有相同元素的新数组,但现在可以节省空间。
Arrays类通常有许多处理数组的好方法。
同时
确保每次添加元素时,不仅要将数组增加一个元素,这一点很重要。最好实施一些策略,您只需每隔一段时间调整一次数组大小。 调整数组大小是一项代价高昂的操作。
答案 1 :(得分:18)
是否有更有效的成长方式 一个大型数组而不是创建一个新数组 并复制所有的价值观?喜欢, 将它与一个新的连接?
没有。并且可能没有语言,这保证了数组的增长总是在没有复制的情况下发生。为数组分配空间并执行其他操作后,很可能在数组结束后的内存中有其他对象。那时,基本上不可能在不复制阵列的情况下扩展阵列。
拥有固定大小的数组怎么样? 存储在另一个数组中并重新分配 /复制那个顶级的?会是 保留实际值?
你的意思是拥有一个数组数组并将其视为一个包含底层数组串联的大数组?是的,这将起作用(“通过间接做假”方法),就像在Java中一样,Object[][]只是指向Object[]个实例的指针数组。
答案 2 :(得分:6)
数组是常量大小,因此无法增长它们。您只能使用 System.arrayCopy 复制它们才能有效。
ArrayList 完全符合您的需求。除非你投入相当长的时间,否则它的优化程度要比我们任何人都要好得多。它在内部使用System.arrayCopy。
更重要的是,如果你有一些巨大的阶段,你需要增长/减少的列表,以及其他不增长/减少的列表,你可以在其中进行数千次读取或写入。假设你有一个巨大的性能需求,你认为ArrayList在读/写时太慢了。您仍然可以将ArrayList用于一个巨大的阶段,并将其转换为另一个的数组。请注意,只有在您的申请阶段很庞大时,这才会有效。
答案 3 :(得分:4)
链接列表如何与仅包含引用的数组相结合。
链表可以增长而无需分配新内存,该阵列可确保您轻松访问。每次数组变小时,您只需将整个数组删除,然后再从链表中重新构建它。
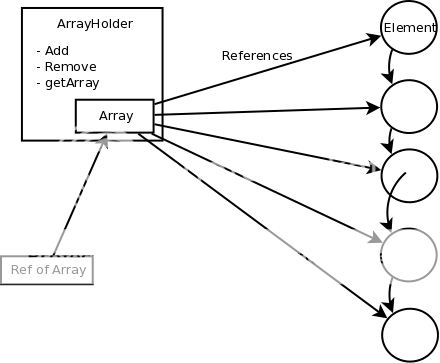
答案 4 :(得分:3)
“我可以不用增长阵列吗? 暂时拥有所有价值观 两次?“
即使您复制数组,您也只会拥有所有值一次。除非你在你的值上调用clone(),否则它们会通过引用传递给新数组。
如果你已经在内存中拥有了你的值,那么复制到一个新数组时唯一的额外内存费用是分配新的Object []数组,它根本不占用太多内存,因为它只是一个指针列表价值对象。
答案 5 :(得分:1)
答案 6 :(得分:1)
AFAIK增长或减少数组的唯一方法是进行System.arraycopy
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to removed.
* @return the element that was removed from the list.
* @throws IndexOutOfBoundsException if index out of range <tt>(index
* < 0 || index >= length)</tt>.
*/
public static <T> T[] removeArrayIndex(T[] src, int index) {
Object[] tmp = src.clone();
int size = tmp.length;
if ((index < 0) && (index >= size)) {
throw new ArrayIndexOutOfBoundsException(index);
}
int numMoved = size - index - 1;
if (numMoved > 0) {
System.arraycopy(tmp, index + 1, tmp, index, numMoved);
}
tmp[--size] = null; // Let gc do its work
return (T[]) Arrays.copyOf(tmp, size - 1);
}
/**
* Inserts the element at the specified position in this list.
* Shifts any subsequent elements to the rigth (adds one to their indices).
*
* @param index the index of the element to inserted.
* @return the element that is inserted in the list.
* @throws IndexOutOfBoundsException if index out of range <tt>(index
* < 0 || index >= length)</tt>.
*/
public static <T> T[] insertArrayIndex(T[] src, Object newData, int index) {
Object[] tmp = null;
if (src == null) {
tmp = new Object[index+1];
} else {
tmp = new Object[src.length+1];
int size = tmp.length;
if ((index < 0) && (index >= size)) {
throw new ArrayIndexOutOfBoundsException(index);
}
System.arraycopy(src, 0, tmp, 0, index);
System.arraycopy(src, index, tmp, index+1, src.length-index);
}
tmp[index] = newData;
return (T[]) Arrays.copyOf(tmp, tmp.length);
}
答案 7 :(得分:1)
显然,如果你连接数组或将它们复制过来,这里的重要部分就不是;更重要的是你的阵列增长战略。不难看出,增长阵列的一种非常好的方法是在它变满时总是加倍。这样,您将把添加元素的成本转为O(1),因为实际的生长阶段只会相对很少发生。
答案 8 :(得分:1)
数组本身是大的,还是引用大型ReferenceTypes?
PrimitiveType数组与数十亿个元素以及包含数千个元素的数组之间存在差异,但它们引用大类实例。
int[] largeArrayWithSmallElements = new int[1000000000000];
myClass[] smallArrayWithLargeElements = new myClass[10000];
编辑:
如果您使用ArrayList进行性能考虑,我可以向您保证,它将与Array索引一样或多或少地执行。
如果应用程序具有有限的内存资源,您可以尝试使用ArrayList的初始大小(其中一个构造函数)。
为了获得最佳的内存效率,您可以使用ArrayList of Arrays创建一个容器类。
类似的东西:
class DynamicList
{
public long BufferSize;
public long CurrentIndex;
ArrayList al = new ArrayList();
public DynamicList(long bufferSize)
{
BufferSize = bufferSize;
al.add(new long[BufferSize]);
}
public void add(long val)
{
long[] array;
int arrayIndex = (int)(CurrentIndex / BufferSize);
if (arrayIndex > al.size() - 1)
{
array = new long[BufferSize];
al.add(array);
}
else
{
array = (long[])al.get(arrayIndex);
}
array[CurrentIndex % BufferSize] = val;
}
public void removeLast()
{
CurrentIndex--;
}
public long get(long index)
{
long[] array;
int arrayIndex = (int)(index / BufferSize);
if (arrayIndex < al.size())
{
array = (long[])al.get(arrayIndex);
}
else
{
// throw Exception
}
return array[index % BufferSize];
}
}
(我的java生锈了,所以请耐心等待......)
答案 9 :(得分:1)
这样做的一种方法是拥有一个数组节点的链表。这有点复杂,但前提是:
您有一个链接列表,列表中的每个节点都引用一个数组。这样,您的阵列可以在不复制的情况下成长。为了增长,您只需要在最后添加其他节点。因此,“昂贵的”增长操作仅发生在每个M操作中,其中M是每个节点的大小。当然,这假设您总是追加到最后并且不会删除。
在这种结构中插入和移除非常复杂,但是如果你可以避免它们那么那就完美了。
这种结构的唯一损失(忽略插入和删除)与gets。获得的时间会略长一些;访问正确的节点需要访问链表中的正确节点,然后在那里获取。如果中间有很多访问,这可能会很慢,但 技巧可以加速链接列表。
答案 10 :(得分:1)
您是否看过GNU Trove高效的Java集合?它们的集合直接存储原语,以便更好地使用内存。
答案 11 :(得分:0)
Heres添加和删除集合/ arraylist / vector中元素所花费的时间基准
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?