是否存在递归函数和内存堆栈之间的直接关系,更多解释请考虑代码:
public static int triangle(int n) {
System.out.println(“Entering: n = ” + n);
if (n == 1) {
System.out.println(“Returning 1”);
return 1;
} else {
int temp = n + triangle(n - 1);
System.out.println(“Returning“ + temp);
return temp;
}
}
在这个例子中,值2,3,4,5将被存储,直到函数返回?请注意它们将在LIFO中返回(LastInFirstOut)这些是递归的特殊情况,它处理内存堆栈还是它们总是在一起?
答案 0 :(得分:2)
是的,递归函数和内存堆栈之间存在直接关系,因为某些具有上限的函数会因为达到堆栈大小限制而导致程序崩溃,并且函数将覆盖程序代码的部分(我们称之为堆栈 - 溢出)。
R:递归
I:Iterative
first call:
R | I
|_| |_|
second call:
R | I
|_| |_|
|_|
third call:
R | I
|_| |_|
|_|
|_|
.
.
.
n call :
R | I
|_| |_|
|_|
|_|
.
.
.
|_|
我希望这是有道理的,因为迭代调用函数将被推送到堆栈一旦完成它从堆栈中断开,下一个调用将加载一个类似的函数,另一方面递归函数加载到堆栈并调用本身并在每次调用时重新加载堆栈,然后在达到停止条件时它们开始关闭(LIFO最后一个调用第一个)。
所以现在具体到你的问题,你所说的n值将在满足停止条件时保存在内存中然后最后一个函数将显示n,然后退出以将手提供给刚刚调用的函数它也会显示自己的n值,同样的事情将被重复,直到第一个函数被调用,但迭代函数将显示一个计数器n的值(只使用一个变量,我们正在改变它的值)。 / p>
以下是关于stackoverflow的好文章,
非常深或无限的递归主要文章:无限递归 堆栈溢出的最常见原因是过深或无限 递归。像Scheme这样实现尾调用的语言 优化,允许特定排序尾的无限递归 递归 - 在没有堆栈溢出的情况下发生。这是因为 尾递归调用不会占用额外的堆栈空间。
答案 1 :(得分:2)
假设这是一个C ++类方法,调用triangle(n)会将数据推送到堆栈,如下所示:
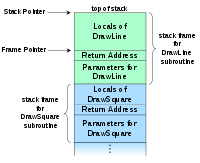
function code int *returnAddress int n 在函数返回之前,不会分配返回值。 R.S. Shaw为Call Stack wikipedia page here提供了一个很好的图像示例。
每次递归时,此数据会被推送到调用堆栈的顶部,因此最后一次调用triangle(n)的代码将位于顶部。存储在*returnAddress中的值是内存中需要放置结果才能展开递归的位置。
换句话说,结果本身(例如:1表示三角形(1),3表示三角形(2))最终位于堆栈的function code部分的某个位置,而不是位于特定的命名位置记忆。如果您运行调试器,则应该能够通过在returnAddress功能代码中放置断点来追踪triangle的位置。
顺便说一句,这不是递归的特例。这是经典的教科书案例。
答案 2 :(得分:0)
临时变量n将在堆栈上,因为它将是调用n-1的参数,因为它将是返回地址。这些都在同一堆栈上。
答案 3 :(得分:0)
正如QuentinQK所解释的那样,局部变量n将消耗堆栈空间以及函数的返回地址 - 并且 - 在短时间内 - 返回值和移交给递归函数的所有参数消耗堆栈上的空间。这发生在每个递归级别上。所以它取决于你的递归有多深(这个函数自称的频率)最终需要多少堆栈,以及它是否突然爆发。
由于这个原因,它必须具有sim最终条件。在你的excaple中,这是if (n==1)' condition where the recursion is stopped when that value is reached. It only works along with the n-1 in the parameter list of the recursive call of三角形。
但是你真的想要知道什么?
{kind=link}