XOM规иҢғеҢ–йңҖиҰҒеӨӘй•ҝж—¶й—ҙ
жҲ‘жңүдёҖдёӘеҸҜд»ҘеӨ§еҲ°1GBзҡ„XMLж–Ү件гҖӮжҲ‘жӯЈеңЁдҪҝз”ЁXOMжқҘйҒҝе…ҚOutOfMemory ExceptionsгҖӮ
жҲ‘йңҖиҰҒ规иҢғеҢ–ж•ҙдёӘж–ҮжЎЈпјҢдҪҶ规иҢғеҢ–йңҖиҰҒеҫҲй•ҝж—¶й—ҙпјҢеҚідҪҝеҜ№дәҺ1.5 MBж–Ү件д№ҹжҳҜеҰӮжӯӨгҖӮ
иҝҷе°ұжҳҜжҲ‘жүҖеҒҡзҡ„пјҡ
жҲ‘жңүиҝҷдёӘзӨәдҫӢXMLж–Ү件пјҢжҲ‘йҖҡиҝҮеӨҚеҲ¶ItemиҠӮзӮ№жқҘеўһеҠ ж–ҮжЎЈзҡ„еӨ§е°ҸгҖӮ
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Packet id="some" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Head>
<PacketId>a34567890</PacketId>
<PacketHeadItem1>12345</PacketHeadItem1>
<PacketHeadItem2>1</PacketHeadItem2>
<PacketHeadItem3>18</PacketHeadItem3>
<PacketHeadItem4/>
<PacketHeadItem5>12082011111408</PacketHeadItem5>
<PacketHeadItem6>1</PacketHeadItem6>
</Head>
<List id="list">
<Item>
<Item1>item1</Item1>
<Item2>item2</Item2>
<Item3>item3</Item3>
<Item4>item4</Item4>
<Item5>item5</Item5>
<Item6>item6</Item6>
<Item7>item7</Item7>
</Item>
</List>
</Packet>
жҲ‘з”ЁдәҺ规иҢғеҢ–зҡ„д»Јз ҒеҰӮдёӢпјҡ
private static void canonXOM() throws Exception {
String file = "D:\\PACKET.xml";
FileInputStream xmlFile = new FileInputStream(file);
Builder builder = new Builder(false);
Document doc = builder.build(xmlFile);
FileOutputStream fos = new FileOutputStream("D:\\canon.xml");
Canonicalizer outputter = new Canonicalizer(fos);
System.out.println("Query");
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
System.out.println("Canon");
outputter.write(nodes);
fos.close();
}
еҚідҪҝиҝҷдёӘд»Јз ҒйҖӮз”ЁдәҺе°Ҹж–Ү件пјҢ规иҢғеҢ–йғЁеҲҶеңЁжҲ‘зҡ„ејҖеҸ‘зҺҜеўғпјҲ4gb ramпјҢ64bitпјҢeclipseпјҢwindowsпјүдёҠзҡ„1.5mbж–Ү件еӨ§зәҰйңҖиҰҒ7еҲҶй’ҹ
йқһеёёж„ҹи°ўд»»дҪ•жңүе…іжӯӨ延иҝҹеҺҹеӣ зҡ„жҢҮзӨәгҖӮ
PSгҖӮжҲ‘йңҖиҰҒ规иҢғеҢ–ж•ҙдёӘXMLж–ҮжЎЈдёӯзҡ„ж®өд»ҘеҸҠж•ҙдёӘж–ҮжЎЈжң¬иә«гҖӮеӣ жӯӨпјҢдҪҝз”Ёж–ҮжЎЈжң¬иә«дҪңдёәеҸӮж•°еҜ№жҲ‘дёҚиө·дҪңз”ЁгҖӮ
жңҖдҪі
3 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ1)

memory is not restriction

main thread is green and no blocking. it is using as much cpu as it can.
because my machine has multi-cores , so the CPU total usage is not full.
But it will be full for a single CPU the main thread is running on.

Nodes.contains is the most busy one
еҶ…йғЁиҠӮзӮ№еңЁListдёӯиҝӣиЎҢз®ЎзҗҶпјҢ并иҝӣиЎҢзәҝжҖ§жҜ”иҫғгҖӮ еҲ—иЎЁдёӯзҡ„жӣҙеӨҡйЎ№зӣ®пјҢвҖңеҢ…еҗ«вҖқе°Ҷжӣҙж…ўгҖӮ
private final List nodes;
public boolean contains(Node node) {
return nodes.contains(node);
}
жүҖд»Ҙ
- е°қиҜ•дҝ®ж”№libзҡ„д»Јз Ғд»ҘдҪҝз”ЁHashMapжқҘдҝқеӯҳиҠӮзӮ№гҖӮ
- жҲ–дҪҝз”ЁеӨҡзәҝзЁӢжқҘеҲ©з”ЁжӣҙеӨҡзҡ„CPUпјҢеҰӮжһңдҪ зҡ„XMLеҸҜд»ҘеҲҶжҲҗе°Ҹзҡ„xmlsгҖӮ
е·Ҙе…·пјҡJVisualVMгҖӮ http://docs.oracle.com/javase/6/docs/technotes/guides/visualvm/index.html
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ0)
з”ұдәҺжӮЁеёҢжңӣеәҸеҲ—еҢ–ж•ҙдёӘж–ҮжЎЈпјҢеӣ жӯӨеҸҜд»ҘзӣҙжҺҘжӣҝжҚў
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
outputter.write(nodes);
дёҺ
outputter.write(doc);
еңЁз»ҷе®ҡиҠӮзӮ№еҲ—иЎЁиҖҢдёҚд»…д»…жҳҜж №иҠӮзӮ№иҝӣиЎҢ规иҢғеҢ–ж—¶пјҢзңӢиө·жқҘCanonicalizerеҒҡдәҶйўқеӨ–зҡ„е·ҘдҪңпјҲдҫӢеҰӮwhunmrжҸҗеҲ°зҡ„nodes.contains()и°ғз”ЁпјүгҖӮ
еҰӮжһңиҝҷдёҚиө·дҪңз”ЁжҲ–иҖ…дёҚеӨҹпјҢжҲ‘дјҡеҲҶеҸүCanonicalizer并жҢүз…§еҲҶжһҗзҡ„е»әи®®иҝӣиЎҢдјҳеҢ–гҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
еҰӮжһңжӮЁж„ҝж„Ҹж”ҫејғXOMпјҢжҲ‘еҸҜиғҪдјҡи§ЈеҶіжӮЁзҡ„й—®йўҳгҖӮжҲ‘зҡ„и§ЈеҶіж–№жЎҲеҢ…жӢ¬дҪҝз”ЁXPath APIе’ҢApache SantuarioгҖӮ
жҖ§иғҪе·®ејӮд»ӨдәәеҚ°иұЎж·ұеҲ»пјҢдҪҶжҲ‘и®ӨдёәжҸҗдҫӣжҜ”иҫғдјҡеҫҲеҘҪгҖӮ
еҜ№дәҺжөӢиҜ•пјҢжҲ‘дҪҝз”ЁдәҶжӮЁеңЁй—®йўҳдёӯжҸҗдҫӣзҡ„1.5MBзҡ„XMLж–Ү件гҖӮ
XOMжөӢиҜ•
FileInputStream xmlFile = new FileInputStream("input.xml");
Builder builder = new Builder(false);
Document doc = builder.build(xmlFile);
FileOutputStream fos = new FileOutputStream("output.xml");
nu.xom.canonical.Canonicalizer outputter = new nu.xom.canonical.Canonicalizer(fos);
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
outputter.write(nodes);
fos.close();
XPath / SantuarioжөӢиҜ•
org.apache.xml.security.Init.init();
DocumentBuilderFactory domFactory = DocumentBuilderFactory.newInstance();
domFactory.setNamespaceAware(true);
DocumentBuilder builder = domFactory.newDocumentBuilder();
org.w3c.dom.Document doc = builder.parse("input.xml");
XPathFactory xpathFactory = XPathFactory.newInstance();
XPath xpath = xpathFactory.newXPath();
org.w3c.dom.NodeList result = (org.w3c.dom.NodeList) xpath.evaluate("./descendant-or-self::node()|./@*", doc, XPathConstants.NODESET);
Canonicalizer canon = Canonicalizer.getInstance(Canonicalizer.ALGO_ID_C14N_OMIT_COMMENTS);
byte canonXmlBytes[] = canon.canonicalizeXPathNodeSet(result);
IOUtils.write(canonXmlBytes, new FileOutputStream(new File("output.xml")));
з»“жһң
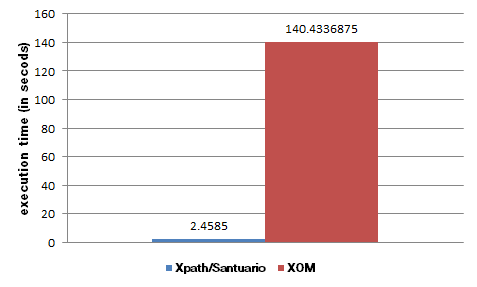
дёӢйқўжҳҜдёҖдёӘд»Ҙз§’дёәеҚ•дҪҚзҡ„з»“жһңиЎЁгҖӮжөӢиҜ•иҝӣиЎҢдәҶ16ж¬ЎгҖӮ
в•”в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•Ұв•җв•җв•җв•җв•җв•җв•җв•җв•җв•Ұв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•—
в•‘ Test в•‘ Average в•‘ Std. Dev. в•‘
в• в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җ╬в•җв•җв•җв•җв•җв•җв•җв•җв•җ╬в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•Ј
в•‘ XOM в•‘ 140.433 в•‘ 4.851 в•‘
в• в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җ╬в•җв•җв•җв•җв•җв•җв•җв•җв•җ╬в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•Ј
в•‘ XPath/Santuario в•‘ 2.4585 в•‘ 0.11187 в•‘
в•ҡв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•©в•җв•җв•җв•җв•җв•җв•җв•җв•җв•©в•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•җв•қ
жҖ§иғҪе·®ејӮеҫҲеӨ§пјҢдёҺXML Path Languageзҡ„е®һж–Ҫжңүе…ігҖӮдҪҝз”ЁXPath / Santuarioзҡ„зјәзӮ№жҳҜе®ғ们дёҚеғҸXOMйӮЈд№Ҳз®ҖеҚ•гҖӮ
жөӢиҜ•иҜҰжғ…
жңәеҷЁпјҡиӢұзү№е°”й…·зқҝi5 4GBеҶ…еӯҳ
SOпјҡDebian 6.0 64bit
JavaпјҡOpenJDK 1.6.0_18 64bit
XOMпјҡ1.2.8
Apache Santuarioпјҡ1.5.3
- еҠ е…ҘйңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- ж–№жі•йңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- ReportDocument.ExportToDiskпјҲпјүиҖ—ж—¶еӨӘй•ҝ
- XOM规иҢғеҢ–йңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- зҙ§еҮ‘йңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- requestLocationUpdatesйңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- removeFromSuperviewпјҲпјүйңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- еҗҲжҲҗйңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- пјҡappпјҡtransformClassesAndResourcesWithProguardForReleaseйңҖиҰҒеӨӘй•ҝж—¶й—ҙ
- SplashscreenиҖ—ж—¶еӨӘй•ҝ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ