假设我有一个整数列表,其中每个元素都是1到20之间的数字。(这不是我想要排序的。)
现在,我有一个“操作”数组,其中每个操作:
编辑:每个操作的每个添加,删除和预防都可以有零个或多个数字,每个数字都可以某些操作在每组中出现零次或多次。对于任何给定的操作,添加和删除是不相交的,阻止和删除是不相交的,但添加和预防可能重叠。
我想对每个操作排序操作数组:
如果出现循环依赖关系,操作链应删除尽可能多的数字和通知我它无法删除所有数字。
此类算法的名称/实现是否优于我下面的算法?
已添加8/23:赏金用于考虑排序要求,同时考虑OpCodes(结构集)和InstructionSemantics(来自枚举的位标志集)。
后来添加8/23:我通过启发式预先排序源数组,实现了89:1的性能提升。有关详细信息,请参阅我当前的答案。
namespace Pimp.Vmx.Compiler.Transforms
{
using System;
using System.Collections.Generic;
using System.Reflection.Emit;
internal interface ITransform
{
IEnumerable<OpCode> RemovedOpCodes { get; }
IEnumerable<OpCode> InsertedOpCodes { get; }
IEnumerable<OpCode> PreventOpCodes { get; }
InstructionSemantics RemovedSemantics { get; }
InstructionSemantics InsertedSemantics { get; }
InstructionSemantics PreventSemantics { get; }
}
[Flags]
internal enum InstructionSemantics
{
None,
ReadBarrier = 1 << 0,
WriteBarrier = 1 << 1,
BoundsCheck = 1 << 2,
NullCheck = 1 << 3,
DivideByZeroCheck = 1 << 4,
AlignmentCheck = 1 << 5,
ArrayElementTypeCheck = 1 << 6,
}
internal class ExampleUtilityClass
{
public static ITransform[] SortTransforms(ITransform[] transforms)
{
throw new MissingMethodException("Gotta do something about this...");
}
}
}
<小时/> 编辑:在这一行下面是关于我实际在做什么的背景信息,以防人们想知道我为什么这么问。它不会改变问题,只显示范围。
我有一个系统,它读入一个项目列表并将其发送到另一个“模块”进行处理。每个项目都是我在编译器中的中间表示中的指令 - 基本上是从1到约300的数字加上大约17个可用修饰符(标志枚举)的某种组合。处理系统(机器代码汇编程序)的复杂性与可能的唯一输入(数字+标志)的数量成比例,我必须手动编码每个处理程序。最重要的是,我必须编写至少3个独立的处理系统(X86,X64,ARM) - 我可以用于多个处理系统的实际处理代码量很少。
通过在阅读和处理之间插入“操作”,我可以确保某些项目永远不会出现进行处理 - 我这样做是通过用其他数字表示数字和/或标志来实现的。我可以通过描述其效果在黑盒子中对每个“转换操作”进行编码,这为我节省了大量的操作复杂性。每次转换操作都很复杂且独特,但比处理系统容易得多。为了显示这节省了多少时间,我的一个操作通过用大约6个数字(没有标志)写出他们想要的效果来完全删除6个标志。
为了把东西放在黑盒子里,我想要一个排序算法来完成我写的所有操作,命令它们产生最大的影响,并告诉我我在简化最终到达的数据方面取得的成功处理系统。当然,我的目标是中间表示中最复杂的项目,并在可能的情况下将它们简化为基本指针算法,这在汇编器中最容易处理。 :)
尽管如此,我还会补充一点。操作效果在指令列表中被描述为“属性效果”。一般情况下,操作表现良好,但有些只会删除其他数字之后的数字(例如删除不跟随16的所有6)。其他人删除包含特定标志的特定号码的所有实例。我稍后会处理这些问题 - 在我找出上面列出的保证添加/删除/阻止的基本问题之后。
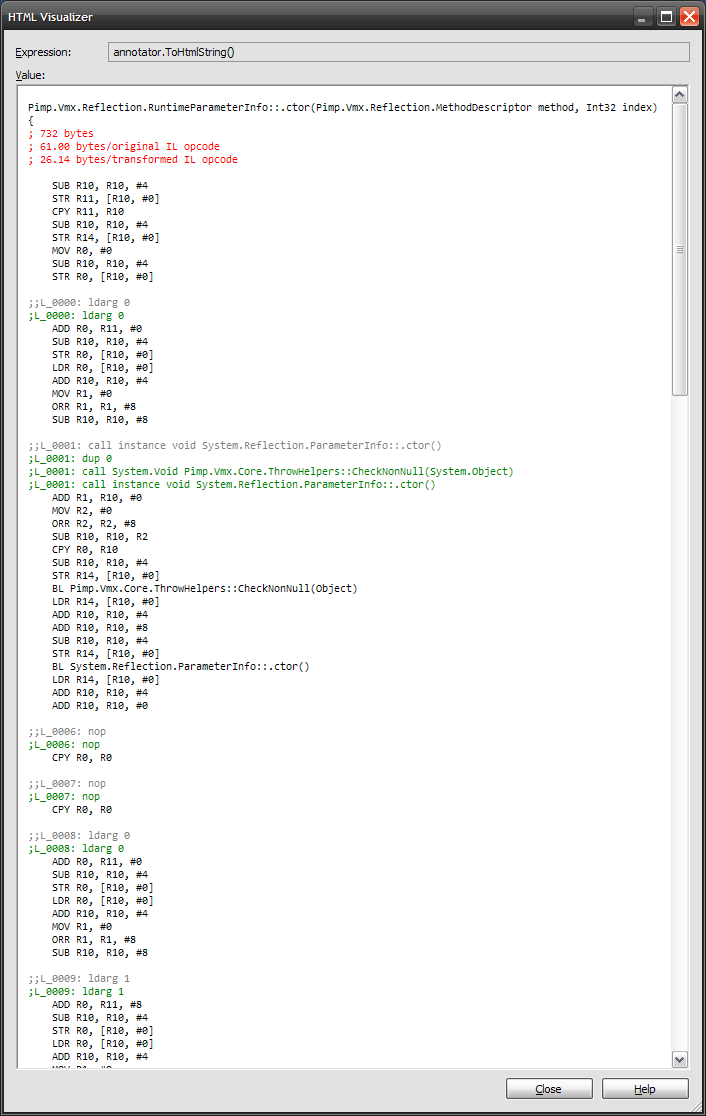
已添加8/23: In this image,您可以看到call已处理InstructionSemantics.NullCheck的{{1}}指令(灰色)RemoveNullReferenceChecks转换以删除语义标志以换取添加另一个调用(没有附加到调用的语义)。现在汇编程序不需要理解/处理InstructionSemantics.NullCheck,因为它永远不会看到它们。不批评ARM代码 - it's a placeholder for now。
答案 0 :(得分:3)
听起来像topological sort,将每个操作视为有向图中的节点,边缘是您提到的约束。
修改: @280Z28对此答案发表了评论:
我现在正在使用拓扑排序,但它在技术上太强大了。我需要某种方法来获得“弱”边缘组(该组的一个或多个边缘保持在最终排序中)
我不确定我是否关注弱组边缘,如果这是指断开周期然后拓扑排序可以做到这一点,我这样做是为了维护 in count ,显示有多少未访问的节点指向此节点。然后,对于每次迭代,您使用最小 in count 的(其中一个)节点,如果计数中的不为零,则意味着存在一个循环而您随意中断循环以完成排序。
答案 1 :(得分:2)
这适用于现在。 当且仅当存在满足条件的排序时,它才会找到它。我还没有尝试优化它。它通过跟踪前一操作不允许添加哪些项目来反向工作。
编辑:我无法将此标记为答案,因为我已经从中获得了巨大的成绩,我只有17次操作(ITransform s)。现在需要15秒才能排序lol / fail。
已添加8/23:检查下一个代码部分,了解我如何将排序改进为实际可行的内容。
编辑8/25:当我越过25个项目时,事情再次变得令人讨厌,但事实证明我在预先排序中遇到了一个小问题,现在已经解决了。
private static ITransform[] OrderTransforms(ITransform[] source)
{
return OrderTransforms(
new List<ITransform>(source),
new Stack<ITransform>(),
new HashSet<OpCode>(source.SelectMany(transform => transform.RemovedOpCodes)),
source.Aggregate(InstructionSemantics.None, (preventedSemantics, transform) => preventedSemantics | transform.RemovedSemantics)
);
}
private static ITransform[] OrderTransforms(List<ITransform> source, Stack<ITransform> selected, HashSet<OpCode> preventAdd, InstructionSemantics preventSemantics)
{
if (source.Count == 0 && preventAdd.Count == 0)
return selected.ToArray();
for (int i = source.Count - 1; i >= 0; i--)
{
var transform = source[i];
if ((preventSemantics & transform.InsertedSemantics) != 0)
continue;
if (preventAdd.Intersect(transform.InsertedOpCodes).Any())
continue;
selected.Push(transform);
source.RemoveAt(i);
#if true
var result = OrderTransforms(source, selected, new HashSet<OpCode>(preventAdd.Except(transform.RemovedOpCodes).Union(transform.PreventOpCodes)), (preventSemantics & ~transform.RemovedSemantics) | transform.PreventSemantics);
#else // this is even slower:
OpCode[] toggle = preventAdd.Intersect(transform.RemovedOpCodes).Union(transform.PreventOpCodes.Except(preventAdd)).ToArray();
preventAdd.SymmetricExceptWith(toggle);
var result = OrderTransforms(source, selected, preventAdd, (preventSemantics & ~transform.RemovedSemantics) | transform.PreventSemantics);
preventAdd.SymmetricExceptWith(toggle);
#endif
if (result != null)
return result;
source.Insert(i, transform);
selected.Pop();
}
return null;
}
为了收回我的赏金,我通过启发式预处理数组,将排序时间从15380s减少到173ms,紧接着是上面的排序路由。
private static ITransform[] PreSortTransforms(ITransform[] source)
{
// maps an opcode to the set of transforms that remove it
ILookup<OpCode, ITransform> removals =
source
.SelectMany(transform => transform.RemovedOpCodes.Select(opcode => new
{
OpCode = opcode,
Transform = transform
}))
.ToLookup(item => item.OpCode, item => item.Transform);
// maps an opcode to the set of transforms that add it
ILookup<OpCode, ITransform> additions =
source
.SelectMany(transform => transform.InsertedOpCodes.Select(opcode => new
{
OpCode = opcode,
Transform = transform
}))
.ToLookup(item => item.OpCode, item => item.Transform);
// maps a set of items (A) to a set of items (B), where ALL elements of B must come before SOME element of A
ILookup<IEnumerable<ITransform>, ITransform> weakForwardDependencies =
removals
.SelectMany(item => additions[item.Key].Select(dependency => new
{
Transform = item,
Dependency = dependency
}))
.ToLookup(item => item.Transform.AsEnumerable(), item => item.Dependency);
/* For items in the previous map where set A only had one element, "somewhat" order the
* elements of set B before it. The order doesn't [necessarily] hold when a key from one
* relationship is a member of the values of another relationship.
*/
var ordered =
weakForwardDependencies
.Where(dependencyMap => dependencyMap.Key.SingleOrDefault() != null)
.SelectMany(dependencyMap => dependencyMap.AsEnumerable());
// Add the remaining transforms from the original array before the semi-sorted ones.
ITransform[] semiSorted = source.Except(ordered).Union(ordered).ToArray();
return semiSorted;
}
答案 2 :(得分:1)
我认为你在这里讨论的是排序算法而不是排序算法。那就是你想找到一个列出属性的订单。
如果已经存在满足这些属性的特定排序算法,我会感到惊讶。
请注意,您可能无法找到给定操作集的排序。实际上甚至可能没有偏序/晶格。一个简单的例子是:
op1(adds(1),removes(2))
op2(adds(2),removes(1))
答案 3 :(得分:0)
由于元素X是否可以出现在列表中的下一个元素中,不仅取决于列表中的最后一个元素,还取决于前面的元素,您可以说拓扑排序过于强大。这是一个更普遍的搜索问题,所以我会尝试更通用的解决方案:回溯搜索或动态编程。前者总是可以完成,但有时会非常缓慢;后者将导致更快(但内存更密集)的解决方案,但它需要你找到一个D.P.这个问题的制定并不总是可行的。
{kind=link}