http://farm8.staticflickr.com/7020/6702134377_cf70482470_z.jpg
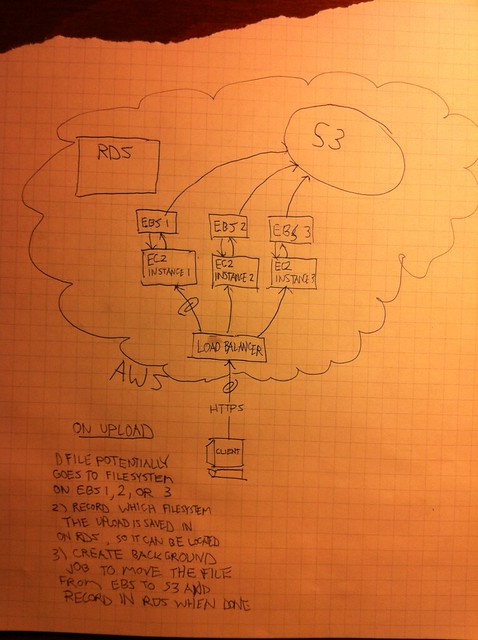
对于可怕的绘画,对不起,但这似乎是一种更好的方式来组织我的想法并传达它们。我一直在努力研究如何创建一个最佳的去耦合易于扩展的系统,用于将文件上传到AWS上的Web应用程序。
直接上传到S3会有效,除了上传者需要立即访问文件进行操作这一事实,然后一旦被操纵,他们就可以进入s3,在那里他们将被提供给所有实例。
我想到了创建一个类似glusterfs的SAN的想法,然后直接上传到那个并从中提供服务。我没有排除它,但是从各种来源来看,这个解决方案的可靠性可能不太理想(如果有人对此有更好的了解,我很乐意听到)。无论如何,我想制定一个更“开箱即用”(在AWS的背景下)解决方案。
因此,为了详细说明这个图,我希望将文件上传到它碰巧去的实例的本地文件系统,这是一个EBS卷。文件的存储位置不会提供给公众(即/ tmp / uploads /)实例仍然可以通过PHP中的readfile()操作访问它,以便用户可以在上传后立即查看和操作它。一旦用户完成操作文件,就可以在SQS中排队将其移动到s3的消息。
我的问题是,一旦我将文件“本地”保存在实例上(可能是由于负载均衡器而导致的任何实例),我如何记录它所在的实例(在数据库中)以便后续请求通过PHP读取或移动文件将找到所述文件。
如果有更多经验的人有一些见解,我将非常感激。谢谢。
答案 0 :(得分:4)
我建议不同的设计可以解决您的问题。
为什么不始终首先将文件写入S3?然后在你正在处理的任何节点上将它复制到本地EBS文件系统(我不太确定你需要做什么操作,但我希望它没关系)。完成修改文件后,只需将其写回S3并从本地EBS卷中删除即可。
通过这种方式,群集中的任何节点都不需要知道哪些节点可能拥有该文件,因为答案是它总是在S3中。通过在本地删除文件,如果另一个节点更新了该文件,您将获得该文件的新版本。
如果每次从S3复制文件太昂贵,你可能会考虑另一件事(它太大了,或者你不喜欢延迟)。您可以在负载均衡器中打开会话关联(AWS称之为粘性会话)。这可以由您自己的cookie或ELB处理。现在来自同一浏览器的后续请求来到同一个群集节点。只需根据S3副本检查本地EBS卷上文件的修改时间,如果更新,则替换。然后,您可以在处理文件的同时利用本地EBS文件系统。
当然,我有很多关于你的系统的东西。为此道歉。
{kind=link}