训练Tesseract为图标加标签
我正在尝试为Tesseract 4.0创建培训数据,以识别屏幕截图中的图标(例如,评论,共享,保存)。这是一个示例屏幕截图:
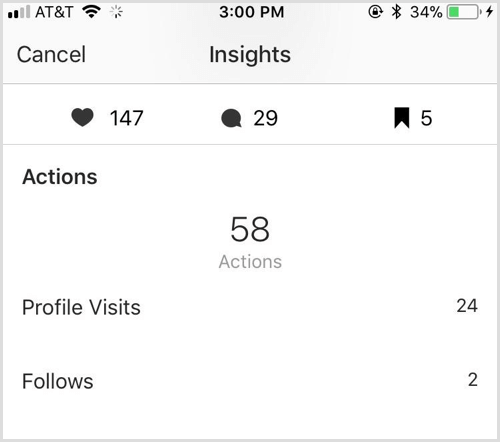
我想微调Tesseract以实现如下输出:
像147
评论29
已保存5
动作
58
动作
个人资料访问24
跟随2
我修改了箱形文件,如下所示:
-心:喜欢
-对话气泡:评论
-书签:已保存
-箭头:分享
但是,最终的训练数据未能按我的意愿读取图标。我得到的错误示例是“像不在unicharset中”。为图标创建unicharset时,我需要做些不同的事情吗?
1 个答案:
答案 0 :(得分:0)
我知道了。框编辑器期望使用单个字母/数字而不是完整的单词。我已经使用Unicode字符来解释我的图标。步骤如下:
- 裁剪所有希望Tesseract检测到的目标图标并将其保存在一个文件中(在我的情况下为own.std.exp0.png )
- 使用命令“ tesseract own.std.exp0.png own.std.exp0 makebox”创建盒子文件
- 打开jTessBoxEditor并在char列中输入unicode。可以在程序字符映射(https://sites.psu.edu/symbolcodes/windows/charmap/)下找到受支持的Unicode列表。示例:对于心脏符号,我使用了U + 2665。请注意,不支持某些unicode。它显示为空白正方形。因此,请继续尝试直到找到可行的方法。我最终编辑的框文件如下所示。

- 创建最终的训练文件,该文件将是own.trainneddata(可以按https://medium.com/apegroup-texts/training-tesseract-for-labels-receipts-and-such-690f452e8f79所示进行操作,也可以使用jTessBoxEditor进行训练)。
- 将own.traineddata复制到目录Tesseract / tessdata,然后使用lang ='own + eng'运行Tesseract。我使用pytesseract,输出如下:

相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?