Pandas和Numpy程序比具有相同功能的循环版慢,如何加快速度?
我有数百万个记录,每个记录都有一个整数(p)和一个X * 3值矩阵。对于每条记录,目标是通过选择标准从矩阵中找到一行(请参见代码中的if语句)。
我是Python的新手,尝试使用并行计算而非循环在Pandas中使用向量化。我已经用两个版本编写了该程序,一个使用Pandas + Numpy,另一个使用简单的循环。
有人告诉我,使用向量化和Numpy数组运算比循环更快。但到目前为止,循环版本的速度提高了约10倍:
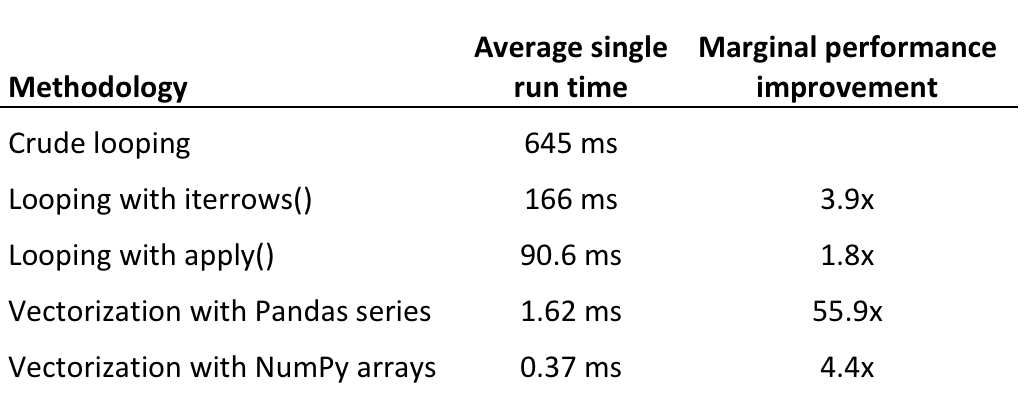
这是程序:
import numpy as np
import pandas as pd
import time
d = {
'values': [np.array([[1400,1400,1800000],[1500,1505,4800000],[1300,1305,5000]]), np.array([[800,900,80000],[1400,1420,50000],[1250,1300,60000]]), np.array([[1700,1750,5000000],[1900,1950,5000000],[1600,1600,3000000]]), np.array([])],
'p': [1300, 1350, 1800, 1400]
}
# The Pandas+Numpy version
def selection_numpy(row):
try:
# Select rows where col[0] >= p
c1 = row['values'][row['values'][:,0] >= row['p']]
# Select rows where col[2] > 1000000
c2 = c1[c1[:,2]>1000000]
# Sort by col[0] and return the lowest row
return c2[c2[:,0].argsort()][0]
except:
pass
start = time.time()
df = pd.DataFrame(d)
df['result'] = df.apply(selection_numpy, axis=1)
# print(df.head())
print(time.time()-start)
# The loop version:
def selection_loop(values, p):
lowest_num = 9999999999
lowest_item = None
# Iterate through each row in the matrix and replace lowest_item if it's lower than the previous one
for item in values:
if item[0] >= p and item[2] > 1000000 and item[0] < lowest_num:
lowest_num = item[0]
lowest_item = item
return lowest_item
start = time.time()
d['result'] = []
for i in range(0, 4):
result = selection_loop(d['values'][i], d['p'][i])
d['result'].append(result)
# print(d['result'])
print(time.time()-start)
两者都产生相同的结果值,但是循环版本的幅度更快(对于实际的百万记录数据集,而不是对于4个示例记录)。
我假设有一个简单而优雅的解决方案,可以为使用矢量化且速度最快的每条记录找到所需的行。不知道为什么使用Numpy数组的函数这么慢,但是我很感谢任何指导。
0 个答案:
没有答案
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?