正则表达式匹配字符串
我正在开发PHP中的“文字过滤器”类,除其他外,需要捕获故意拼写错误的单词。这些单词由用户输入为句子。让我展示一个用户输入的句子的简单例子:
I want a coke, sex, drugs and rock'n'roll
以上示例是正确的短语写法。我的班级会找到可疑的单词sex和drugs,并且会很好。
但我认为用户会试图阻止对单词的检测并将内容写得稍微不同。实际上,他有许多不同的方法来编写相同的单词,以便它对某些类型的人仍然可读。例如,单词sex可以写为s3x或5ex或53x或s e x或s 3 x或s33x或5533xxx ss 33 xxx等等。
我知道正则表达式的基础知识并尝试了下面的模式:
/(\b[\w][\w .'-]+[\w]\b)/g
因为
-
\b字边界 -
[\w]这个词可以以一个字母或一个数字开头...... -
[\w .'-]...后跟任何字母,数字,空格,点,引号或破折号...... -
+...一次或多次...... -
[\w]...以一个字母或一个数字结尾。 -
\b字边界
这部分有效。
如果示例短语写为I want a coke, 5 3 x, druuu95 and r0ck'n'r011,我会得到3个匹配项:
-
I want a coke -
5 3 x -
druuu95 and r0ck'n'r011
我需要的是8场比赛
-
I -
want -
a -
coke -
5 3 x -
druuu95 -
and -
r0ck'n'r011
为了缩短,我需要一个正则表达式给我一个句子的每个单词,即使单词以数字开头,包含可变数量的数字,空格,点,短划线和引号,并以字母结尾或数字。
任何帮助将不胜感激。
1 个答案:
答案 0 :(得分:3)
描述
通常好的单词长度为2个或更多字母(I和a除外)并且不包含数字。这种表达方式并不完美,但确实有助于说明为什么进行这种类型的语言匹配是非常困难的,因为它是创造性的人试图表达自己而不被抓住之间的军备竞赛,以及正在尝试的开发团队抓住瑕疵。
(?:\s+|\A)[#'"[({]?(?!(?:[a-z]{2}\s+){3})(?:[a-zA-Z'-]{2,}|[ia]|i[nst]|o[fnr])[?!.,;:'")}\]]?(?=(?:\s|\Z))|((?:[a-z]{2}\s+){3}|.*?\b)
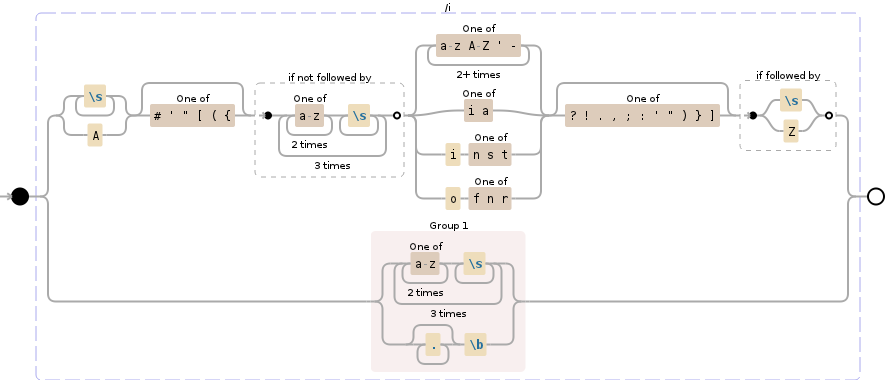
**要更好地查看图像,只需右键单击图像并在新窗口中选择视图
此正则表达式将执行以下操作:
- 找到所有可接受的单词
- 查找所有其余内容并将其存储在Capture Group 1 中
实施例
现场演示
https://regex101.com/r/cL2bN1/1
解释
NODE EXPLANATION
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
\s+ whitespace (\n, \r, \t, \f, and " ") (1
or more times (matching the most amount
possible))
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\A the beginning of the string
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
[#'"[({]? any character of: '#', ''', '"', '[', '(',
'{' (optional (matching the most amount
possible))
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
(?: group, but do not capture (3 times):
----------------------------------------------------------------------
[a-z]{2} any character of: 'a' to 'z' (2 times)
----------------------------------------------------------------------
\s+ whitespace (\n, \r, \t, \f, and " ")
(1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
){3} end of grouping
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[a-zA-Z'-]{2,} any character of: 'a' to 'z', 'A' to
'Z', ''', '-' (at least 2 times
(matching the most amount possible))
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
[ia] any character of: 'i', 'a'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
i 'i'
----------------------------------------------------------------------
[nst] any character of: 'n', 's', 't'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
o 'o'
----------------------------------------------------------------------
[fnr] any character of: 'f', 'n', 'r'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
[?!.,;:'")}\]]? any character of: '?', '!', '.', ',', ';',
':', ''', '"', ')', '}', '\]' (optional
(matching the most amount possible))
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\Z before an optional \n, and the end of
the string
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
(?: group, but do not capture (3 times):
----------------------------------------------------------------------
[a-z]{2} any character of: 'a' to 'z' (2 times)
----------------------------------------------------------------------
\s+ whitespace (\n, \r, \t, \f, and " ")
(1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
){3} end of grouping
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
.*? any character except \n (0 or more times
(matching the least amount possible))
----------------------------------------------------------------------
\b the boundary between a word char (\w)
and something that is not a word char
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?