使用正则表达式去除地址中的换行符
我有一组地址数据,其中包含三个主要列的策略号,地址和索引号。在一些地址的中间有我想要摆脱的新行。但我不想摆脱分隔每个数据行的新行。我正在使用textpad并尝试创建一个正则表达式,可以使用搜索和替换找到我要删除的特定换行符。
每个索引号都是一个随机数后跟“_CDB”,所以我一直在尝试创建一个正则表达式,删除所有不在“_CDB”之前的换行符。所以我当前的表达式使用的lookbehind看起来像下面的(?<!_CDB)\n,但它似乎仍然是找到每一个新行,而不仅仅是那些没有“_CDB”的行。
如果有人可以提出我出错的地方或建议在地址中间消除这些新行的另一种方法,那将是非常好的。
由于
1 个答案:
答案 0 :(得分:1)
描述
你可能会挂在线末端有空格的线上。我只是匹配所有返回字符并捕获_CDB\n,然后只需替换
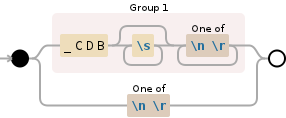
(_CDB\s*[\n\r]+)|[\n\r]
替换为: $1
实施例
现场演示
https://regex101.com/r/qT6nU8/1
示例文字
321321312, 1111 deer park road
kenosha
wi
53144, 1111_CDB
321321312, 222 deer park road
kenosha
wi
53144, 222_CDB
321321312, 333 deer park road
kenosha
wi
53144, 333_CDB
321321312, 4444 deer park road
kenosha
wi
53144, 4444_CDB
替换后
321321312, 1111 deer park roadkenoshawi53144, 1111_CDB
321321312, 222 deer park roadkenoshawi53144, 222_CDB
321321312, 333 deer park roadkenoshawi53144, 333_CDB
321321312, 4444 deer park roadkenoshawi53144, 4444_CDB
解释
NODE EXPLANATION
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
_CDB '_CDB'
----------------------------------------------------------------------
\s* whitespace (\n, \r, \t, \f, and " ") (0
or more times (matching the most amount
possible))
----------------------------------------------------------------------
[\n\r]+ any character of: '\n' (newline), '\r'
(carriage return) (1 or more times
(matching the most amount possible))
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
[\n\r] any character of: '\n' (newline), '\r'
(carriage return)
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?