正则表达式以逃避n#除2#
我试图覆盖Parsedown的标记,只允许<h2>标题。
什么正则表达式会逃避除<h2>以外的所有标题类型?
#Heading -> \#Heading
##Heading -> ##Heading
###Heading -> \###Heading
####Heading -> \####Heading
#####Heading -> \#####Heading
######Heading -> \######Heading
3 个答案:
答案 0 :(得分:1)
您可以使用此正则表达式
^ #Start of string
(?! #Negative lookahead(it means, whatever is there next do not match it)
##\w #Assert that its impossible to match two # followed by a word character
)
(?= #Positive lookahead
# #check if there is at least one #
)
<强> Regex Demo
正则表达式细分
\w denotes any character from [A-Za-z0-9_].
[..] denotes character class. Any character(not string) present in this will be matched.
注意
{{1}}
答案 1 :(得分:1)
描述
^((?:#|#{3,})[^#])
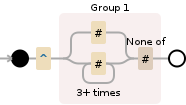
替换为: \$1
此正则表达式将执行以下操作:
- 匹配一个哈希
- 匹配3个或更多哈希
实施例
现场演示
https://regex101.com/r/kE4oK6/1
示例文字
#Heading
##Heading
###Heading
####Heading
#####Heading
######Heading
样本匹配
\#Heading
##Heading
\###Heading
\####Heading
\#####Heading
\######Heading
解释
NODE EXPLANATION
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
# '#'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
#{3,} '#' (at least 3 times (matching the
most amount possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
[^#] any character except: '#'
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
答案 2 :(得分:1)
使用预测标题,但不是双重哈希:
^(?!##\w)(?=#+)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?