有一次我注意到Windows没有在特定核心上保留计算密集型线程 - 它保持切换核心。所以我推测这项工作会更快完成,如果 线程将保持对相同数据缓存的访问。真的,我能够观察到 将线程的亲和性掩码设置为单个核心后,速度提高了约1% (在ppmd(de)压缩线程中)。 但后来我尝试为这种效果构建一个简单的演示,或多或少失败 - 也就是说,它在我的系统上按预期工作(Q9450):
buflog=21 bufsize=2097152 (cache flush) first run = 6.938s time with default affinity = 6.782s time with first core only = 6.578s speed gain is 3.01%
但我问过的人并不能完全重现这种效果。 有什么建议吗?
#include <stdio.h>
#include <windows.h>
int buflog=21, bufsize, bufmask;
char* a;
char* b;
volatile int r = 0;
__declspec(noinline)
int benchmark( char* a ) {
int t0 = GetTickCount();
int i,h=1,s=0;
for( i=0; i<1000000000; i++ ) {
h = h*200002979 + 1;
s += ((int&)a[h&bufmask]) + ((int&)a[h&(bufmask>>2)]) + ((int&)a[h&(bufmask>>4)]);
} r = s;
t0 = GetTickCount() - t0;
return t0;
}
DWORD WINAPI loadcore( LPVOID ) {
SetThreadAffinityMask( GetCurrentThread(), 2 );
while(1) benchmark(b);
}
int main( int argc, char** argv ) {
if( (argc>1) && (atoi(argv[1])>16) ) buflog=atoi(argv[1]);
bufsize=1<<buflog; bufmask=bufsize-1;
a = new char[bufsize+4];
b = new char[bufsize+4];
printf( "buflog=%i bufsize=%i\n", buflog, bufsize );
CreateThread( 0, 0, &loadcore, 0, 0, 0 );
printf( "(cache flush) first run = %.3fs\n", float(benchmark(a))/1000 );
float t1 = benchmark(a); t1/=1000;
printf( "time with default affinity = %.3fs\n", t1 );
SetThreadAffinityMask( GetCurrentThread(), 1 );
float t2 = benchmark(a); t2/=1000;
printf( "time with first core only = %.3fs\n", t2 );
printf( "speed gain is %4.2f%%\n", (t1-t2)*100/t1 );
return 0;
}
P.S。如果有人需要,我可以发布已编译版本的链接。
答案 0 :(得分:3)
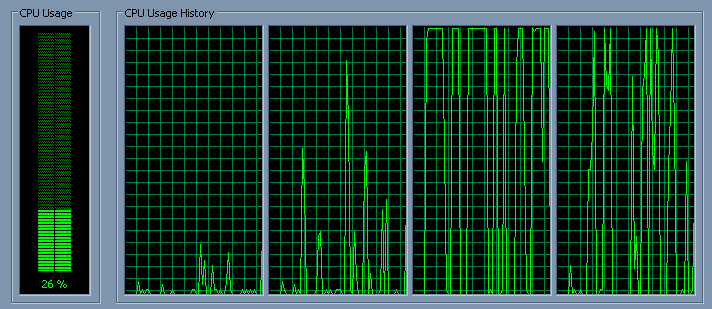
默认亲和力: default affinity http://nishi.dreamhosters.com/u/paf_a0.png
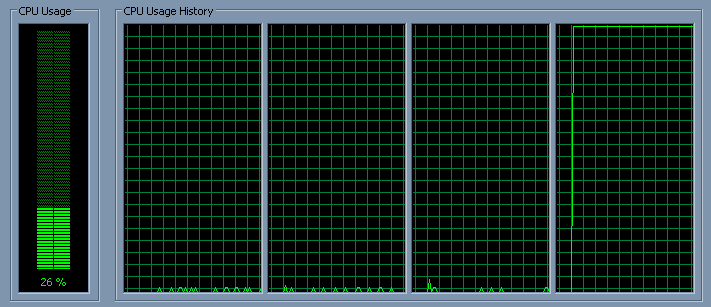
亲和力设置为核心#4 affinity set to core #4 http://nishi.dreamhosters.com/u/paf_a8.png
现在,这是一个归档者。你真的认为工人的线程正在进行吗? 在cpu周围都可以吗?
答案 1 :(得分:0)
也许你只是幸运,而在你测试程序的其他PC上,有人做了与你完全相同的事情,但他的线程已经沉睡了很多。
这将导致您的程序不时被中断,当另一个线程被安排时。
答案 2 :(得分:0)
答案 3 :(得分:0)
您如何知道线程使用的其他3个内核而不是某些系统线程?例如,如果您正在寻呼或其他什么。在perfmon中为您的流程设置一些性能计数器,并验证这一假设。
{kind=link}
{kind=link}