如何过滤掉python正则表达式中的模式,直到输入的单词
在python中,我想提取一个特定的子字符串,直到提供输入字。
考虑以下字符串: -
"Name: abc and Age:24"
我想分别提取字符串"Name : abc and"和"Age:24"。
我目前正在使用以下模式:
re.search(r'%S+\s*:[\S\s]+',pattern).
但是o / p是整个字符串。
3 个答案:
答案 0 :(得分:1)
您可以使用re.findall:
>>> import re
>>> s="Name: abc and Age:24"
>>> re.findall(r'[A-Za-z]+:[a-z\s]+|[A-Za-z]+:\d+',s)
['Name: abc and ', 'Age:24']
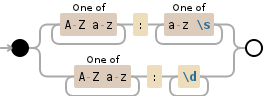
在字符串中的前一个模式中,键(Age和Name)以大写字母开头,您可以使用[A-Za-z]+来匹配它们。它将匹配任何大写和小写的组合len为1或更多的字母,但对于:之后的其余字符串,您可以使用小写字母,对于第二部分也是相同的。但对于第二部分:之后的字符串,您只需匹配长度为1或更长的数字!
如果:之后您可能在第二部分中使用了字符串,则可以使用\w代替\d:
>>> re.findall(r'[A-Za-z]+:[a-z\s]+|[A-Za-z]+:\w+',s)
['Name: abc def ghi ', 'Location:Earth']
答案 1 :(得分:0)
您需要使用re.findall。
>>> s = "Name: abc and Age:24"
>>> re.findall(r'\S+\s*:.*?(?=\s*\S+\s*:|$)', s)
['Name: abc and', 'Age:24']
>>> re.findall(r'[^\s:]+\s*:.*?(?=\s*[^\s:]+\s*:|$)', s)
['Name: abc and', 'Age:24']
-
[^\s:]+匹配任何字符,但不匹配:或空格一次或多次。所以这与关键部分相匹配。 -
\s*:匹配零个或多个空格和冒号符号。 -
.*?非贪婪地匹配零个或多个,直到 -
(?=\s*[^\s:]+\s*:|$)关键部分或行尾。(?=...)称为正向前瞻,它断言匹配是否可能。它不匹配任何单个字符。
或
您可以使用re.split。
>>> re.split(r'\s+(?=[^\s:]+\s*:)', s)
['Name: abc and', 'Age:24']
答案 2 :(得分:0)
您可以使用此正则表达式:
\w+[:]\w+|\w+[:](\s)\w+|\w+(\s)[:]\w+
以下是细分:
\w+[:]\w+
\ w表示得到一个单词,[:]表示获取冒号字符,+符号表示获取冒号前面的单词。其余部分则相反:)
| symbol只是一个OR运算符,我用它来检查空格是跟随还是在冒号之前。
它会得到冒号之前和之后的单词。它也可以在冒号之前或之后有空格时使用。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?