иҜ•еӣҫеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸ
жҲ‘дёҖзӣҙиҜ•еӣҫеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸж— жөҺдәҺдәӢгҖӮжҲ‘йңҖиҰҒеҒҡзҡ„жҳҜеҒҡдёҖдёӘйқһиҙӘе©Әзҡ„еҢ№й…ҚпјҢеңЁиҝҷз§Қжғ…еҶөдёӢе°ҶжңҖж–°зҡ„ж•°еӯ—дёҺзү№е®ҡзҡ„еҚ•иҜҚеҢ№й…ҚпјҡдёӢдёҖжӯҘпјҡ
д»ҘдёӢжҳҜж–Үеӯ—пјҡ
<a href="/forum/view-forum/standard-trading-shops/page/1">Prev</a>
<a href="/forum/view-forum/standard-trading-shops/page/1">1</a>
<a class="current" href="/forum/view-forum/standard-trading-shops/page/2">2</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">3</a>
<a href="/forum/view-forum/standard-trading-shops/page/4">4</a>
<span class="separator">...</span><a href="/forum/view-forum/standard-trading-shops/page/3029">3029</a>
<a href="/forum/view-forum/standard-trading-shops/page/3030">3030</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">Next</a>
жҲ‘йңҖиҰҒжүҫеҲ°3030дҪңдёәжҲ‘зҡ„зӯ”жЎҲпјҢ延伸жҳҜиҜҘж®өиҗҪдёӯзҡ„жңҖй«ҳж•°еӯ—гҖӮ
жҲ‘еҺҢеҖҰдәҶеҒҡд»Җд№Ҳпјҡ
(/d)+.*?Next
然иҖҢпјҢиҝҷжҖ»жҳҜеҢ№й…ҚпјҲ1пјү第дәҢиЎҢзҡ„第дёҖдёӘж•°еӯ—иҖҢдёҚжҳҜжңҖй«ҳзҡ„ж•°еӯ—3030.жҲ‘зҡ„зҗҶи§ЈжҳҜ.*?жү§иЎҢйқһиҙӘе©Әзҡ„еҢ№й…ҚпјҢе®ғеә”еҢ№й…ҚжңҖж–°зҡ„еҢ№й…ҚгҖӮ
д»»дҪ•дәәйғҪеҸҜд»Ҙеё®еҠ©жҲ‘еҗ—пјҹ и°ўи°ў дёӯеҸ·
3 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ1)
^[\s\S]*>(\d+)<
дҪ еҸҜд»ҘиҜ•иҜ•иҝҷдёӘгҖӮжҠ“дҪҸgroup 1жҲ–capture 1гҖӮзңӢзңӢжј”зӨәгҖӮ
https://regex101.com/r/sJ9gM7/28
иҝҷйҮҢдҪ greedy matchжңҖеӨҡnumberгҖӮжүҖд»Ҙиҝҷе°ҶеҒңз•ҷеңЁ><д№Ӣй—ҙжңҖеҗҺдёҖж¬ЎеҮәзҺ°зҡ„ж•°еӯ—гҖӮ.й»ҳи®Өжғ…еҶөдёӢдёҺж–°иЎҢдёҚеҢ№й…ҚпјҢжүҖд»ҘиҰҒд№ҲеҸҜд»ҘдҪҝз”ЁDOTALLжҲ–[\s\S]гҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ0)
дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸи§ЈжһҗHTMLйҖҡеёёжҳҜдёҚжҳҺжҷәзҡ„гҖӮиҜҘзҪ‘з«ҷи§ЈйҮҠдәҶеҺҹеӣ 并дёәжӮЁжҸҗдҫӣдәҶжүҖжңүдё»иҰҒиҜӯиЁҖзҡ„жӣҙеҘҪйҖүжӢ©гҖӮ
жӮЁе°ҡжңӘжҢҮе®ҡжӮЁжӯЈеңЁдҪҝз”Ёе“Әз§ҚиҜӯиЁҖпјҢдҪҶжӯӨжӯЈеҲҷиЎЁиҫҫејҸйҖӮз”ЁдәҺеӨ§еӨҡж•°жғ…еҶөпјҡ
(\d+)(?:<[^>]+>[^<]*){2}Next
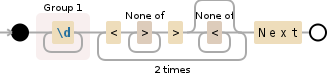
иҜҘеҸ·з Ғе°ҶеңЁз¬¬дёҖдёӘжҚ•иҺ·з»„дёӯгҖӮе®һйҷ…дёҠпјҢжҲ‘иҰҒиҜҙзҡ„жҳҜпјҢеңЁ{2} <дёӘ>дёӘе®һдҫӢеҗҺпјҢ>д№ӢеүҚзҡ„д»»дҪ•еӯ—з¬ҰйғҪдёҚжҳҜ<пјҢиҖҢдё”еҸҜиғҪжҳҜжҹҗдәӣеӯ—з¬ҰдёҚжҳҜ<something> t NextзӣҙеҲ°дёӢдёҖдёӘе®һдҫӢгҖӮеңЁ{{1}}зҡ„иҝҷдёӨдёӘе®һдҫӢд№ӢеҗҺеә”иҜҘжҳҜеҚ•иҜҚ{{1}}гҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
дҪҝз”ЁBeautifulSoupжҳҜи§ЈжһҗHTMLзҡ„йҰ–йҖүж–№жі•гҖӮ
s = """<a href="/forum/view-forum/standard-trading-shops/page/1">Prev</a>
<a href="/forum/view-forum/standard-trading-shops/page/1">1</a>
<a class="current" href="/forum/view-forum/standard-trading-shops/page/2">2</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">3</a>
<a href="/forum/view-forum/standard-trading-shops/page/4">4</a>
<span class="separator">...</span><a href="/forum/view-forum/standard-trading-shops/page/3029">3029</a>
<a href="/forum/view-forum/standard-trading-shops/page/3030">3030</a>
<a href="/forum/view-forum/standard-trading-shops/page/3">Next</a>"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(s)
text = soup.text.splitlines()
index = text.index('Next')
result = text[index-1]
>>> print result
3030
дёҚеҰӮжӯЈеҲҷиЎЁиҫҫејҸйӮЈд№Ҳдјҳйӣ…пјҢдҪҶиҝҷжҳҜжӯЈзЎ®зҡ„ж–№жі•гҖӮ
- е°қиҜ•дҪҝз”ЁPowerShellдёӯзҡ„жӯЈеҲҷиЎЁиҫҫејҸжқҘеҢ№й…Қе®ғ
- иҜ•еӣҫеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҡPHP
- иҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸиҜ•еӣҫеңЁTCLдёӯеҢ№й…Қд»Җд№Ҳ
- иҜ•еӣҫдёҺжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…Қ
- жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚиҝҷдёҖзӮ№
- иҜ•еӣҫеҢ№й…Қ* / *жӯЈеҲҷиЎЁиҫҫејҸ
- иҜ•еӣҫеңЁjavaдёӯеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸпјҡ
- иҜ•еӣҫеҢ№й…ҚиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸ
- дёҖдёӘRegExеҢ№й…ҚиҝҷдёӘ
- иҜ•еӣҫеҢ№й…ҚйҮҚж–°
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ