Java匹配报价内容
Extract data from Specific format CSV files
数据格式列在上面的链接中。
基本上,我想用引号来提取所有字段,如:
'data0,data1,data2,,,','.........'
我使用这样的正则表达式:
String subrow = row.replaceFirst("'\\w.*?',",",");
这将始终匹配一对引号中的第一个内容。
然而,有这样的情况:
例如
data1 = "encoding = 'utf-8'"
仍然如果我使用上面的方法,它将匹配:
'data0,encoding='
除了
'data0,encoding='utf-8',data2,,,'
然后如何修改正则表达式以匹配一对引号中的内容,即使其中还有另一对引号? (零或一对报价)
PS:将在测试中使用文本:
'1415561780,84,0,130,52','0,0,0,97517573,0,0,0,0,0,,,','corpvpn,ac103f20,57771,42eb9375,80,0','4,http%3a%2f%2flenovoappssystemupdateprod.112.2o7.net%2fb%2fss%2flenovoappssystemupdateprod%2f6,,0,0,,text/xml; encoding='utf-8',595,207,595,161,595,0,1,0,0,0,ac10ff1b,18604,42eb9375,80,0,','200,text/xml,text/xml,64,64,481,64,472,64,0,0,0',,,,,
请注意有一个:
encoding='utf-8'
在第四对引号内。
1 个答案:
答案 0 :(得分:1)
如果我了解您的问题,您希望='foo'成为匹配的一部分,该匹配也位于'...'内。在这种情况下,您可以尝试使用此正则表达式
'\\w(=\\s*'[^']*'|[^'])*'
正则表达式的一些解释
-
|代表OR - 类似
[abc]的结构是character class - 它会匹配一个字符,在此示例中为ab或c -
[^abc]是否定字符类 - 它会接受任何 不ab或{{1} } -
c表示空格(例如空格,\\s,\t,\n...) -
\r表示可在单词中使用的字符(\\w0-9a-z和下划线A-Z) -
_是量词,这意味着它之前的元素可以显示为零{或}次,如*可以接受ab*aaaaba{{ 1}}等等。
现在解释我的正则表达式
abba 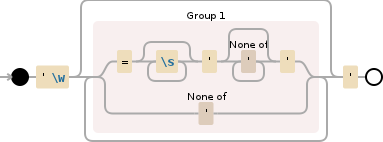
-
abbba代表零个或多个不是'\w(=\s*'[^']*'|[^'])*'的字符。如果我们使用[^']*'来围绕'这将代表以'[^']*'开头和结尾但内部不再有'的文字,因此如果是{{1}这样的文字它可以匹配''foo' bar 'baz'。它类似于'foo'。 - 但不是简单的
'baz'我决定在第一个'.*?'和最后一个'[^']*'之间添加案例,而不是非'- 字符我们也可以接受一系列'(例如')。
演示:
='...'输出:
='utf-8'
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?