正则表达式 - 带空格和小数逗号的数字
我想在Pyhton中为以下类型的字符串编写正则表达式:
1 100
1 567 865
1 474 388 346
即。数字与千分之几。这是我的正则表达式:
R"(\ d {1,3}(?:\ S * \ d {3})*)
它工作正常。但是,我也想解析
1 100,34848
1 100 300,8
19 328 383 334,23499
即。用十进制数字分隔的数字。我写了
RR = R"(\ d {1,3}(?:\ S * \ d {3})*)?(\ d +)\ S
它不起作用。例如,如果我做
句子=" jsjs 2 222,11 dhd"
re.findall(rr,sentence)
[(' 2 222',',11')]
感谢任何帮助,谢谢。
3 个答案:
答案 0 :(得分:0)
这有效:
import re
rr=r"(\d{1,3}(?:\s*\d{3})*(?:,\d+)?)"
sentence = "jsjs 2 222,11 dhd"
print re.findall(rr, sentence) # prints ['2 222,11']
答案 1 :(得分:0)
TL; DR:此常规表达将打印['2 222,11 ']
r"(?:\d{1,3}(?:\s*\d{3})*)(?:,\d+)?"
搜索的结果是括号中的表达,除了那些从(?:开始的表达式或整个表达式(如果不是任何子表达式)
所以在你的第一个正则表达式中它将匹配你的字符串并返回整个表达式,因为没有子表达式(唯一的parenteses以(?:开头)
在第二个中它将找到字符串2 222,11并匹配它,然后它查看子表达式(\d{1,3}(?:\s*\d{3})*)和(,\d+),并返回包含这些的元组:即小数点前的部分
因此,为了修复您的表达,您需要添加到所有括号?:或删除它们
最后\s也是多余的,因为正则表达式总是匹配尽可能多的字符 - 这意味着它将匹配逗号后的所有数字
答案 2 :(得分:0)
您的结果唯一的问题是您获得了两个匹配组而不是一个。发生这种情况的唯一原因是您要创建两个捕获组而不是一个捕获组。你在上半场和下半场分别设置了括号,这就是括号的意思。不要那样做,你就不会遇到这个问题。
所以,有了这个,你就到了中途:
(\d{1,3}(?:\s*\d{3})*,\d+)\s
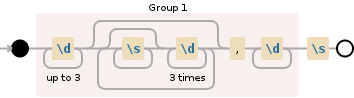
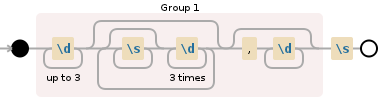
唯一的问题是,\d+部分现在是强制而不是可选的。你显然需要在某处放置?,正如你所做的那样。但没有一个团体,你怎么做?简单:您可以使用群组,只需将其设为非捕获群组((?:…)而不是(…))。并把它放在主捕获组内,而不是与它分开。正如您已经为重复的\s*\d{3}部分所做的那样。
(\d{1,3}(?:\s*\d{3})*(?:,\d+)?)\s
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?