如何从字符串中的某个索引开始使用re.search?
似乎是一件简单的事,但我没有看到它。如何在字符串中间开始搜索?
1 个答案:
答案 0 :(得分:7)
re.search函数不像start方法那样采用str参数。但是,已编译的re.compile / re.RegexObject模式的search方法会采用pos参数。
如果您考虑一下,这是有道理的。如果你真的需要反复使用相同的正则表达式,你可能应编译它们。与效率无关 - 缓存可以很好地适用于大多数应用程序 - 但只是为了可读性。
但是如果你需要使用顶级函数怎么办呢,因为你不能出于某种原因预先编译你的模式呢?
嗯,有很多第三方正则表达式库。其中一些包装PCRE或谷歌的RE2或ICU,有些从头开始实现正则表达式,它们都至少有一些略有不同,有时完全不同的API。
但是regex模块,它被设计为stdlib中re的最终替代品(虽然它现在被撞了几次因为它不是非常准备好)可以作为re的替代品,以及(在其他扩展中)它的pos函数需要endpos和search个参数。< / p>
通常情况下,您想要这样做的最常见原因是在我刚发现的那个之后找到下一场比赛&#34;并且有更简单的方法来做到这一点:使用finditer代替search。
例如,这个str方法循环:
i = 0
while True:
i = s.find(sub, i)
if i == -1:
break
do_stuff_with(s, i)
...转换为这个更好的正则表达式循环:
for match in re.finditer(pattern, s):
do_stuff_with(match)
如果不合适,您可以随时切片:
match = re.search(pattern, s[index:])
但是这会产生一半字符串的额外副本,如果string实际上是12GB mmap,则可能会出现问题。 (当然对于12GB mmap的情况,你可能想要映射一个新窗口......但有些情况下它不会有帮助。)
最后,您始终只需修改模式即可跳过index个字符:
match = re.search('.{%d}%s' % (index, pattern), s)
我在这里所做的就是将.{20}添加到模式的开头,这意味着要匹配任何字符的20个,以及您尝试匹配的其他内容。这是一个简单的例子:
.{3}(abc)
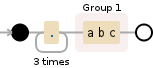
如果我提供此abcdefabcdef,它将匹配第3个字符后的第一个'abc',即第二个abc。
但请注意它与'defabc'实际匹配的内容。因为我使用捕获组作为我的真实模式,并且我没有将.{3}放在一个组中,match.group(1)等等将完全像我想要的那样工作他们,但match.group(0)会给我错误的东西。如果重要的话,你需要向后看。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?