дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–ж•°жҚ®
жҲ‘жӯЈеңЁе°қиҜ•д»Һж—§зҪ‘з«ҷдёӯжҸҗеҸ–ж•°жҚ®гҖӮжҲ‘жңүдёҖдёӘеёҰжңүеҹҺй•ҮеҗҚз§°зҡ„дёӢжӢүеҲ—иЎЁгҖӮжҲ‘жӯЈеңЁе°қиҜ•дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–еҹҺй•ҮеҗҚ称并жҸ’е…Ҙж•°жҚ®еә“гҖӮжҲ‘иҜ•иҝҮ>.*<пјҢдҪҶжІЎжңүеҢ№й…ҚгҖӮжҲ‘еҜ№жӯЈеҲҷиЎЁиҫҫејҸеҫҲж–°пјҢжүҖд»ҘжҲ‘дёҚзҹҘйҒ“еҸ‘з”ҹдәҶд»Җд№ҲгҖӮ
зӨәдҫӢж•°жҚ®еҰӮдёӢгҖӮжҲ‘жғіеңЁз»“жқҹж Үи®°д№ӢеүҚдҪҝз”ЁиҜҘеҗҚз§°гҖӮ
" <option value=""ABERCROMBIE"">ABERCROMBIE</option>"
" <option value=""ABERDEEN"">ABERDEEN</option>"
" <option value=""ABRAMS RIVER"">ABRAMS RIVER</option>"
" <option value=""ACACIAVILLE"">ACACIAVILLE</option>"
2 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
дҪ зҡ„жӯЈеҲҷиЎЁиҫҫејҸеҫҲеҘҪпјҢдҪҶдҪ еҝ…йЎ»зЎ®дҝқе®ғдёҺйқһиҙӘе©Әзҡ„иҝҗз®—з¬Ұ并дҪҝз”ЁжҚ•иҺ·з»„гҖӮдҪ еҸҜд»ҘдҪҝз”ЁиҝҷдёӘжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
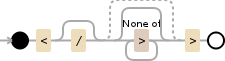
>(.*?)<
<ејә> Working demo
MATCH 1
1. [35-46] `ABERCROMBIE`
MATCH 2
1. [89-97] `ABERDEEN`
MATCH 3
1. [144-156] `ABRAMS RIVER`
MATCH 4
1. [202-213] `ACACIAVILLE`
жӮЁеҸҜд»ҘдҪҝз”ЁжӯӨд»Јз Ғпјҡ
String line = "<YOUR TEXT TO BE PARSED>";
Pattern pattern = Pattern.compile(">(.*?)<");
Matcher matcher = pattern.matcher(line);
while (matcher.find()) {
System.out.println("Town: " + matcher.group(1));
}
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ0)
еҸӘйңҖдҪҝз”ЁPossessive Quantifiers
жӣҝжҚўеҢ…еҗ«з»“жқҹж Үи®°зҡ„<...>д№Ӣй—ҙзҡ„жүҖжңүеҶ…е®№
зӨәдҫӢд»Јз Ғпјҡ
String str="<option value=\"\"ABERCROMBIE\"\">ABERCROMBIE</option>";
System.out.println(str.replaceAll("</?[^>]*+>", "")); // prints ABERCROMBIE
жіЁж„ҸпјҡеҰӮжһңйңҖиҰҒпјҢиҜ·иҮҙз”өtrim()д»ҘеҲ йҷӨйўҶеёҰе’Ңеҹ№и®ӯз©әй—ҙгҖӮ
<\/?[^>]*+>
зӣёе…ій—®йўҳ
- дҪҝз”Ёhtmlдёӯзҡ„regexжҸҗеҸ–ж•°жҚ®
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–ж•°жҚ®
- дҪҝз”Ёregexд»Һеӯ—з¬ҰдёІдёӯжҸҗеҸ–зү№е®ҡж•°жҚ®
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸ
- дҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸ
- Ruby - дҪҝз”Ёregexд»Һеӯ—з¬ҰдёІдёӯжҸҗеҸ–ж•°жҚ®
- дҪҝз”ЁRegExйҖҡиҝҮзү№е®ҡиҫ“еҮәжҸҗеҸ–зү№е®ҡж•°жҚ®
- Java - дҪҝз”ЁRegexд»ҺDocumentдёӯжҸҗеҸ–ж•°жҚ®
- GolangпјҡдҪҝз”ЁRegexжҸҗеҸ–ж•°жҚ®
- еҰӮдҪ•еңЁpythonдёӯдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸжҸҗеҸ–ж•°жҚ®пјҹ
жңҖж–°й—®йўҳ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ