Node.js看起来很有趣,但是我必须错过一些东西 - 不是Node.js只调整为在单个进程和线程上运行吗?
那么它如何扩展多核CPU和多CPU服务器?毕竟,尽可能快速地制作单线程服务器,但是对于高负载我想要使用多个CPU。同样可以使应用程序更快 - 似乎今天的方式是使用多个CPU并并行化任务。
Node.js如何适应这张照片?它的想法是以某种方式分发多个实例或什么?
答案 0 :(得分:663)
Node.js绝对可以在多核计算机上进行扩展。
是的,Node.js是每个进程一个线程。这是一个非常慎重的设计决策,无需处理锁定语义。如果您不同意这一点,您可能还没有意识到调试多线程代码是多么的难以理解。有关Node.js流程模型的更深入解释及其工作原理(以及为什么它永远不会支持多个线程),请阅读my other post。
两种方式:
由于v6.0.X Node.js直接包含the cluster module,因此可以轻松设置可以侦听单个端口的多个节点工作程序。请注意,这与通过npm提供的较旧的learnboost“群集”模块不同。
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
http.Server(function(req, res) { ... }).listen(8000);
}
工作人员将竞争接受新的连接,并且负载最少的进程最有可能获胜。它运行良好,可以在多核盒上很好地扩大吞吐量。
如果你有足够的负担来关心多个核心,那么你也想要做更多的事情:
在像Nginx或Apache这样的网络代理后面运行你的Node.js服务 - 可以进行连接限制的东西(除非你想要超载条件完全打开盒子),重写URL,提供静态内容和代理其他子服务。
定期回收您的工作进程。对于长时间运行的过程,即使很小的内存泄漏也会最终累积起来。
设置日志收集/监控
共享端口:nginx (port 80) --> Node_workers x N (sharing port 3000 w/ Cluster)
VS
个别端口:nginx (port 80) --> {Node_worker (port 3000), Node_worker (port 3001), Node_worker (port 3002), Node_worker (port 3003) ...}
单个端口设置可能会带来一些好处(可能会在进程之间产生更少的耦合,有更复杂的负载平衡决策等),但是设置和内置集群模块肯定会更加有效。是一种低复杂性的替代方案,适用于大多数人。
答案 1 :(得分:41)
一种方法是在服务器上运行node.js的多个实例,然后在它们前面放置一个负载均衡器(最好是一个非阻塞的,如nginx)。
答案 2 :(得分:30)
Ryan Dahl去年夏天在the tech talk he gave at Google回答了这个问题。换句话说,“只需运行多个节点进程并使用合理的东西来允许它们进行通信。例如sendmsg() - 样式IPC或传统的RPC”。
如果您想立即弄脏手,请查看 spark2 Forever模块。它使得生成多个节点进程变得非常简单。它处理设置端口共享,因此他们每个都可以接受到同一端口的连接,如果你想确保一个进程在它/什么时候死掉的情况下重新启动进程,它们也会自动重新生成。
更新 - 10/11/11 :节点社区中的共识似乎是Cluster现在是每台计算机管理多个节点实例的首选模块。 Forever也值得一看。
答案 3 :(得分:13)
多节点利用您可能拥有的所有核心 看看http://github.com/kriszyp/multi-node。
对于更简单的需求,您可以在不同的端口号上启动多个节点副本,并在其前面放置一个负载均衡器。
答案 4 :(得分:10)
如上所述,Cluster会在所有核心范围内对您的应用进行扩展和负载均衡。
添加像
cluster.on('exit', function () {
cluster.fork();
});
将重启任何失败的工人。
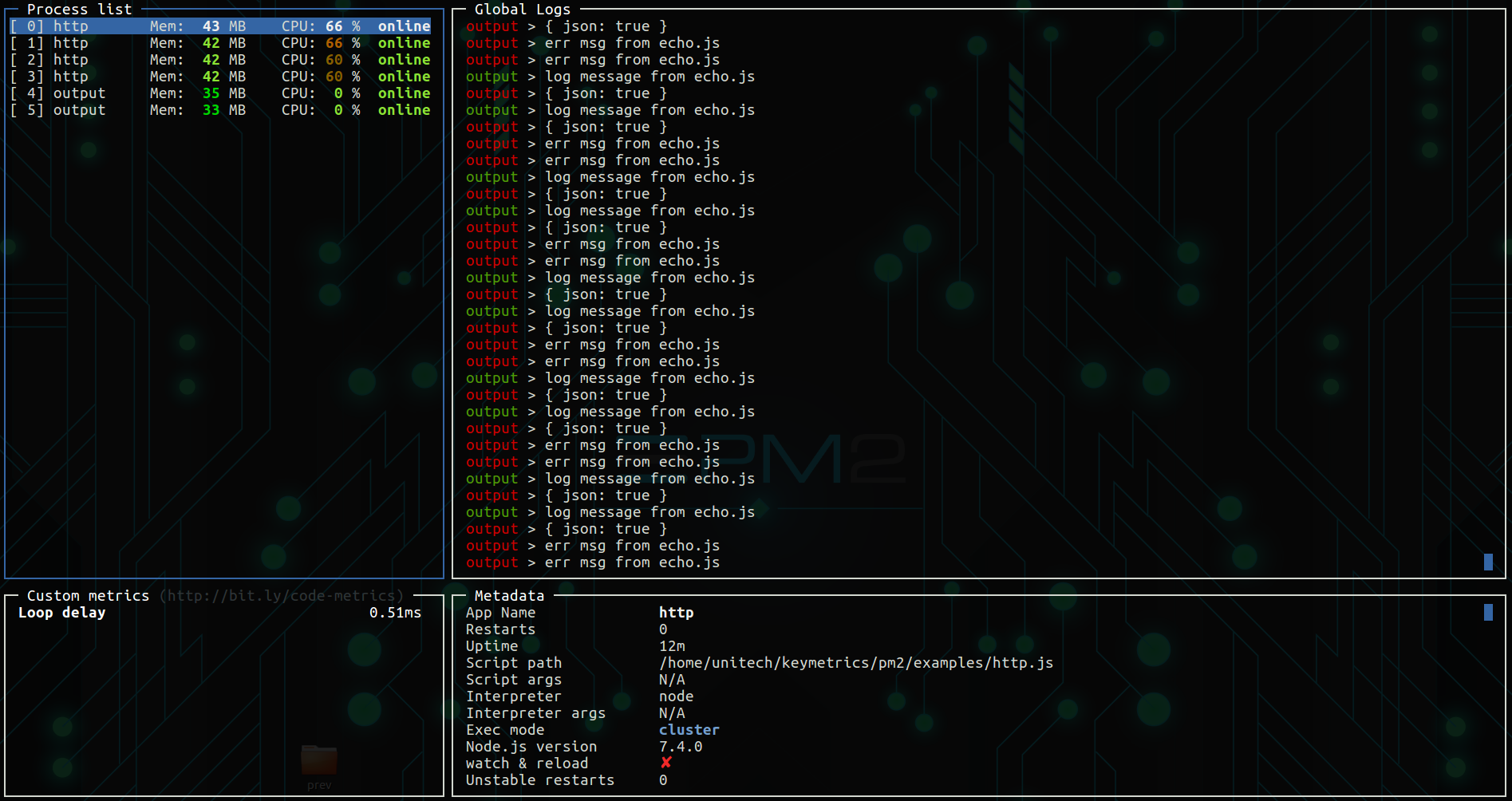
现在,很多人还喜欢PM2,它会为您处理群集,并提供some cool monitoring features。
然后,在使用群集运行的多台计算机前添加Nginx或HAProxy,您可以实现多级故障转移和更高的负载容量。
答案 5 :(得分:7)
节点的未来版本将允许您分叉进程并将消息传递给它,Ryan已经声明他想找到一些方法来共享文件处理程序,因此它不会是一个直接的Web Worker实现。
目前还没有一个简单的解决方案,但现在还很早,节点是我见过的最快的开源项目之一,所以期待在不久的将来有一些很棒的东西。
答案 6 :(得分:7)
Spark2基于Spark,现在不再维护了。 Cluster是它的继任者,它有一些很酷的功能,比如每个CPU核心产生一个工作进程并重新生成死亡工人。
答案 7 :(得分:7)
Node Js正在支持群集以充分利用您的cpu。如果您没有使用群集运行它,那么可能是您在浪费硬件功能。
Node.js中的群集允许您创建可以共享相同服务器端口的单独进程。例如,如果我们在端口3000上运行一个HTTP服务器,则它是一个服务器在单核处理器上的单线程上运行。
下面显示的代码允许您对应用程序进行分组。此代码是Node.js代表的官方代码。
find /usr/local/ -name f951
查看此文章,了解完整的tutorial
答案 8 :(得分:5)
我正在使用Node worker以简单的方式从我的主进程运行进程。在我们等待官方出行的时候,似乎工作得很好。
答案 9 :(得分:5)
这里的新孩子是LearnBoost的"Up"。
它提供了“零停机时间重新加载”,并且还可以创建多个工作程序(默认情况下为CPU的数量,但它是可配置的)以提供所有世界中最好的。
这是新的,但似乎相当稳定,我在我目前的一个项目中愉快地使用它。
答案 10 :(得分:2)
cluster模块允许您使用机器的所有核心。实际上,您只需使用2个命令就可以利用这一点,而无需使用非常流行的流程管理器pm2来触及您的代码。
npm i -g pm2
pm2 start app.js -i max
答案 11 :(得分:1)
您可以通过结合使用cluster模块和os模块来在多个内核上运行node.js应用程序,该模块可以用来检测您有多少个CPU。
例如,假设您有一个server模块,该模块在后端运行简单的http服务器,并且您想在多个CPU上运行它:
// Dependencies.
const server = require('./lib/server'); // This is our custom server module.
const cluster = require('cluster');
const os = require('os');
// If we're on the master thread start the forks.
if (cluster.isMaster) {
// Fork the process.
for (let i = 0; i < os.cpus().length; i++) {
cluster.fork();
}
} else {
// If we're not on the master thread start the server.
server.init();
}
答案 12 :(得分:1)
我必须在集群模式下使用节点构建与 PM2 集群模式等进程管理器之间添加一个重要区别。
PM2 允许您在运行时零停机时间重新加载。
pm2 start app.js -i 2 --wait-ready
在您的代码中添加以下内容
process.send('ready');
当你在代码更新后调用 pm2 reload app 时,PM2 会重新加载
应用程序的第一个实例,等待“就绪”调用,然后继续
重新加载下一个实例,确保您始终有一个应用程序处于活动状态以响应请求。
如果使用nodejs的集群,重启等待服务器准备好会出现宕机时间。
答案 13 :(得分:0)
也可以将Web服务设计为多个监听unix套接字的独立服务器,这样就可以将数据处理等功能推送到单独的进程中。
这类似于大多数scrpting /数据库Web服务器体系结构,其中cgi进程处理业务逻辑,然后通过unix套接字将数据推送到数据库。
不同之处在于数据处理被写为侦听端口的节点web服务器。
它更复杂,但最终还是多核开发必须要去的地方。为每个Web请求使用多个组件的多进程架构。
答案 14 :(得分:0)
使用纯TCP负载均衡器(HAProxy)在每个运行一个NodeJS进程的多个框前面,可以将NodeJS扩展到多个框。
如果您具有在所有实例之间共享的一些常识,则可以使用中央Redis商店或类似商品,然后可以从所有流程实例(例如,从所有框)访问
{kind=link}