我在未知的维空间中有一系列点,例如:
data=numpy.array(
[[ 115, 241, 314],
[ 153, 413, 144],
[ 535, 2986, 41445]])
我希望找到所有点之间的平均欧氏距离。
请注意,我有超过20,000点,所以我希望尽可能高效地完成这项工作。
感谢。
答案 0 :(得分:11)
如果您可以访问scipy,可以尝试以下操作:
答案 1 :(得分:4)
嗯,我不认为有一种超快的方法可以做到这一点,但是应该这样做:
tot = 0.
for i in xrange(data.shape[0]-1):
tot += ((((data[i+1:]-data[i])**2).sum(1))**.5).sum()
avg = tot/((data.shape[0]-1)*(data.shape[0])/2.)
答案 2 :(得分:4)
评估数量无法解决:
但如果你可以使用approximate result,你可以节省所有这些平方根的费用。这取决于你的需求。
如果您要计算平均值,我建议您在计算之前不要尝试将所有值都放入数组中。只计算总和(如果你还需要标准差,则计算平方和),并在计算时丢弃每个值。
自alt text http://www.equationsheet.com/latexrender/pictures/12a8776b729c0f86352787b4f0125226.gif和alt text http://www.equationsheet.com/latexrender/pictures/2c405dc40c555302bfb6183ec34af822.gif以来,我不知道这是否意味着您必须在某处加倍。
答案 3 :(得分:4)
现在您已经说明了寻找异常值的目标,您可能最好还是计算样本均值,以及样本方差,因为这两个操作都会给您一个O(nd)操作。有了这个,您应该能够找到异常值(例如,除了平均值之外的点,而不是std.dev的某些部分),并且过滤过程应该可以在O(nd)时间内执行总计O( ND)。
您可能会对Chebyshev's inequality上的复习感兴趣。
答案 4 :(得分:4)
没有可行的解决方案,优化是否值得?此外,在整个数据集上计算距离矩阵很少需要快速,因为您只需要执行一次 - 当您需要知道两点之间的距离时,您只需查看它,它已经计算好了。
所以,如果你没有地方可以开始,那么这就是一个。如果你想在Numpy中这样做而不需要编写任何内联fortran或C,那应该没问题,尽管你可能想要包含这个名为“numexpr”的小型基于矢量的虚拟机(可在PyPI上找到)在这种情况下,与单独的Numpy相比,性能提升了5倍。
下面我计算了2D空间中10,000个点的距离矩阵(10K x 10k矩阵给出了所有10k点之间的距离)。我的MBP花了59秒。
import numpy as NP
import numexpr as NE
# data are points in 2D space (x, y)--obviously, this code can accept data of any dimension
x = NP.random.randint(0, 10, 10000)
y = NP.random.randint(0, 10, 10000)
fnx = lambda q : q - NP.reshape(q, (len(q), 1))
delX = fnx(x)
delY = fnx(y)
dist_mat = NE.evaluate("(delX**2 + delY**2)**0.5")
答案 5 :(得分:1)
如果您需要快速且不精确的解决方案,则可以调整Fast Multipole Method算法。
以小距离分隔的点对最终平均距离的贡献较小,因此将点组合成簇并比较簇距离是有意义的。
![Sum[n-i, {i, 0, n}] = http://www.equationsheet.com/latexrender/pictures/27744c0bd81116aa31c138ab38a2aa87.gif](http://www.equationsheet.com/latexrender/pictures/27744c0bd81116aa31c138ab38a2aa87.gif){kind=link}
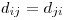{kind=link}
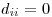{kind=link}