正则表达式从重复中排除值
我正在使用加载文件并尝试编写一个正则表达式,它将检查文件中没有正确数量的分隔符的任何行。让我们假设分隔符是%(我不确定此文本字段是否支持加载文件中的分隔符)。我写的正则表达式找到了所有正确的行:
^%([^%]*%){20}$
有时找到没有正确数量分隔符的行更有利,所以为了实现这一点,我写道:
(^%([^%]*%){0,19}$)|(^%([^%]*%){21,}$)
我很担心这个(以及我一般写的任何正则表达式)的效率,所以我想知道是否有更好的方法来编写它,或者我写它的方式是否正常。我想也许会有一些方法来使用重复令牌的交替,例如:
{0,19}|{21,}
但这似乎不起作用。
如果知道有用,我只是搜索Sublime Text中的文件,我相信它使用PCRE。我也对第一个正则表达式更好的建议持开放态度,尽管我发现即使在特别大的加载文件中也能很好地工作。
1 个答案:
答案 0 :(得分:1)
如果您的正则表达式引擎支持否定前瞻,您可以稍微修改原始正则表达式。
^(?!%([^%]*%){20}$)
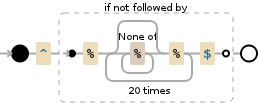
上面的正则表达式仅对测试有用。如果要捕获,则需要添加.*部分。
^(?!%([^%]*%){20}$).*$
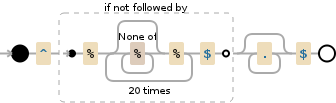
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?