正则表达式在字段中的每个单词的开头找到大写字符
我创建了一个函数,它将一个字段与一个正则表达式进行比较,如果它与模式不匹配则返回0,如果匹配则返回1。我已经创建了类,所以我可以为模式匹配创建一个UDF。
function(expression,rexex) //If it matches it
本周末我一直在研究SQL服务器中的正则表达式,并且处于一个十字路口。
我基本上需要有以下模式,1次传递,0次失败。基本上我希望每个单词的第一个字母都大写:
the dog is bad - 0
The Dog Is Bad - 1
我很惭愧地说,我花了一整天才弄清楚如何识别每件作品的第一个字母,看看它是否是资本。
这是我到目前为止所拥有的。
[\p{Lu}\p{Lt}]
对于正确方向的任何帮助或推动都将不胜感激。
4 个答案:
答案 0 :(得分:0)
这仅假定字母,每个字只有一个空格:
^((?:\b[A-Z][a-z]*\b) {0,1})+$
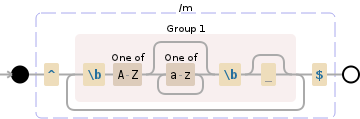
自由间隔:
^ //Start of line
( //(Capture)
(?: //(Non-capture)
\b // Followed by word boundary
[A-Z] // Followed by a capital letter
[a-z]* // Followed by zero or more lowercase letters
\b // Followed by word boundary
) {0,1} // Followed by either no space, or one space
)+ // One or more times
$ //End of line
答案 1 :(得分:0)
答案 2 :(得分:0)
比赛开始(^)后跟一个或多个大写字母组((...)+),后跟零个或多个单词字符([A-Z] )后跟一个或多个空格,或结尾(\w*)。
(\s+|$) 
答案 3 :(得分:0)
由于您似乎想要兼容unicode,我会这样做:
(?:^|\s+)(\p{lu}\p{Ll}*)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?