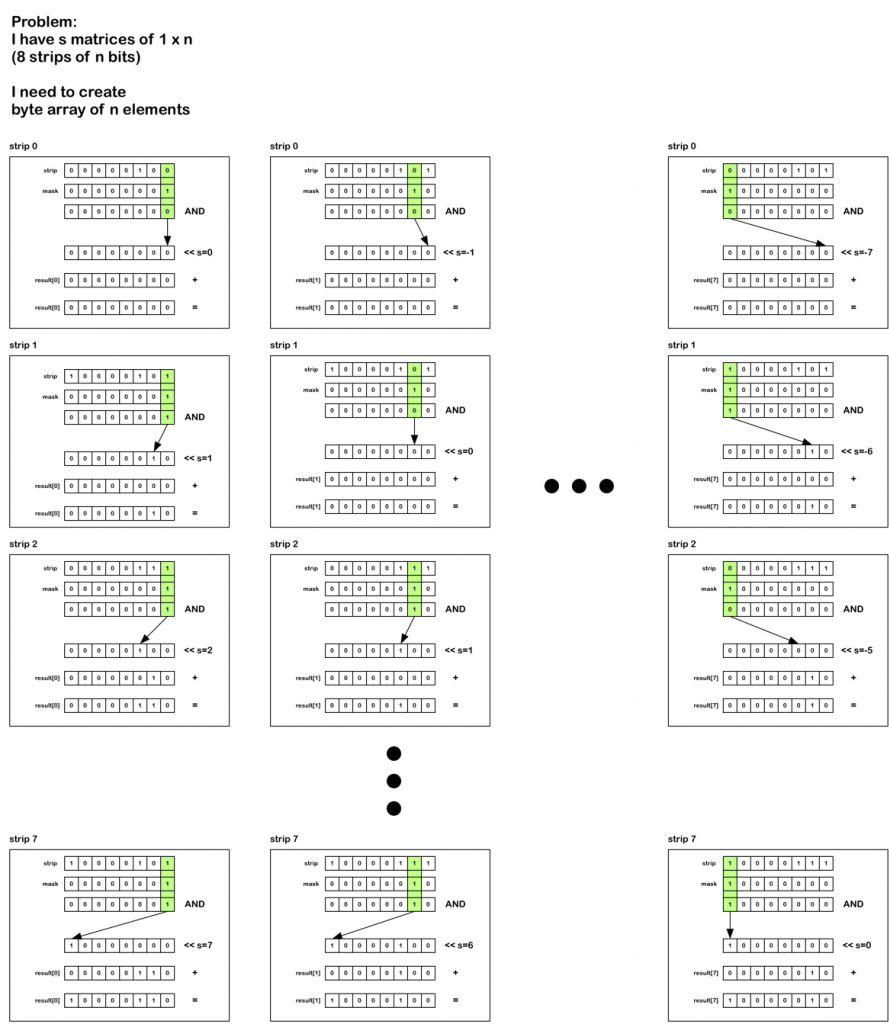
我试图对n个元素的字节数组执行特定8个n位数组的矩阵转换,每个数组都有n位(大约70,000个)。
上下文信息:8个n位数组是8个通道的RGB数据。我需要有一个字节代表8个数组的第n位。这将在ARM Cortex-M3处理器上运行,并且需要尽可能快地执行,因为我使用生成的阵列生成8个同步信号。
我已经提出了一个伪算法(在链接中)来做这件事,但我担心这对处理器来说可能太昂贵了。
我正在寻找执行速度最快的代码。尺寸是次要的。 我会很感激的建议。
这是我实施的,但结果不是那么好。
do{
for(b=0;b<24;b++){ //Optimize to for(b=24;b!=0;b--)
m = 1 << b;
*dataBytes = *dataBytes + __ROR((*s0 & m),32+b-0); //strip 0 data
*dataBytes = *dataBytes + __ROR((*s1 & m),32+b-1); //strip 1 data
*dataBytes = *dataBytes + __ROR((*s2 & m),32+b-2); //strip 2 data
*dataBytes = *dataBytes + __ROR((*s3 & m),32+b-3); //strip 3 data
*dataBytes = *dataBytes + __ROR((*s4 & m),32+b-4); //strip 4 data
*dataBytes = *dataBytes + __ROR((*s5 & m),32+b-5); //strip 5 data
*dataBytes = *dataBytes + __ROR((*s6 & m),32+b-6); //strip 6 data
*dataBytes = *dataBytes + __ROR((*s7 & m),32+b-7); //strip 7 data
dataBytes++;
}
s0 += 3;
s1 += 3;
s2 += 3;
s3 += 3;
s4 += 3;
s5 += 3;
s6 += 3;
s7 += 3;
}while(n--);
S0到7是8个单独的向量,其中的比特以24的组为单位。 N是组的数量,m是掩码,b是掩码位置。 dataBytes是生成的数组。
答案 0 :(得分:0)
优化时总会有两件事情,
您当前的算法一次加载一个字节。您可以通过一次加载至少32位来更有效地完成此操作。这将优化ARM总线。对于某些情况,结束算法不会被BUS绑定,如果是,则为此进行了优化。
对于不同的ARM CPU,有pld等指令可以尝试通过预先提取下一个数据元素来优化BUS。这可能适用于您的Cortex-M,也可能不适用。另一种技术是尽可能将数据重新定位到更快的内存,例如TCM。
像素处理几乎总是通过SIMD类型指令加速。 Cortex-M的指令标记为 SIMD。不要挂在标签上 SIMD ;使用这个概念。如果您已将多个字节加载到单词中,则可以使用表格。
const unsigned long bits[16] = {
0, 1, 0x100, 0x101,
0x10000, 0x10001, 0x10100, 0x10101,
0x1000000, 0x1000001, 0x1000100, 0x1000101,
0x1010000, 0x1010001, 0x1010100, 0x1010101
}
类似的概念用于因特网上的许多CRC算法。处理每个半字节(4位)并一次形成一个位的下一个四字节输出。可能有一个可以替换表的乘法值,但这取决于你的速度倍数,这取决于Cortex-M和/或ARM的类型。
绝对是'C'中的原型,然后转换为汇编程序或尽可能使用内联汇编程序。如果您的算法中有许多mov语句,则表明编译器可能比您更好地分配寄存器。许多复杂的算法使用代码生成器(在phython,perl等中编写脚本),它可以展开你最终的最佳循环,并以算法的方式跟踪寄存器。
注意:仔细检查我的表格;它只是第一个裂缝,我实际上没有编码这个特定的算法。可能有更多光滑的方法一次处理多个位,但这个想法可能很有成效。
{kind=link}