网络链接提取器功能解释?
我一直致力于一个在线课程,它引导我们创建一个为Web链接抓取字符串的函数。您可以看到以下功能:
page = 'This is a <a href="http://udacity.com">Link!</a>.This is a <a href="http://egg.com">Link!</a>.This is a <a href="http://bread.com">Link!</a>'
def get_next_target(page):
start_link = page.find("<a href=")
if start_link == -1:
return None, 0
start_quote = page.find('"', start_link)
end_quote = page.find('"', start_quote +1)
url = page[start_quote + 1: end_quote]
return url, end_quote
def print_all_links(page):
while True:
url, endpos = get_next_target(page)
if url:
print url
page = page[endpos:]
else:
break
print_all_links(page)
但是,我仍然不明白它是如何协同工作的?对我来说,它看起来像两个独立的功能。我理解第一个函数 - (print_all_links(page) - 是如何工作的,但我坚持的是第二部分如何从第一个函数获取信息?
具体而言,while下的if和while声明在做什么?我不明白他们要检查什么,或者他们如何从第一个功能中获取信息。
非常感谢任何帮助。
亲切的问候。 :)
2 个答案:
答案 0 :(得分:2)
get_next_target(page)
这会在页面中找到字符串"<a href="。然后,它会在下一个"之后的链接中提取链接,然后返回另一个"并返回该链接,并且链接"的位置结束于此处。
print_all_links(page)
这会尽可能长地通过get_next_target从页面中获取链接(while True: ...)。它获取下一个链接和结束位置。如果链接文本为None(即找不到链接),则会停止(即else子句)。否则(if url:),它会打印链接地址,并在刚刚提取的链接之后用所有内容替换页面文本,以便删除下一个链接。
答案 1 :(得分:1)
您的整个算法归结为代码的这一部分:
page.find("<a href=")
即。 str.find函数:
string.find(s, sub[, start[, end]])返回s中找到子字符串sub的最低索引,使得sub完全包含在s [start:end]中。失败时返回-1。开始和结束的默认值以及负值的解释与切片相同。
基本上,您的算法的作用是:
- 遍历字符串,从开头或上一个位置开始查找下一个
"<a href="
CF:
start_link = page.find("<a href=")
- 在找到位置之后的引号之间找到引号之间的部分
CF:
start_quote = page.find('"', start_link)
end_quote = page.find('"', start_quote +1)
url = page[start_quote + 1: end_quote]
- 从
""<a href="返回该部分,目标网址和 - 如果
get_next_target函数未返回有效值,则会中断循环 - 否则将其打印出来并以新位置重新开始
get_next_target的当前位置
N.B。:捕获字符串中所有链接的另一种更简单的方法是使用正则表达式:
>>> page = 'This is a <a href="http://udacity.com">Link!</a>.This is a <a href="http://egg.com">Link!</a>.This is a <a href="http://bread.com">Link!</a>'
>>> import re
>>> r = re.compile(r'<a href="([^"]+)">')
>>> r.findall(page)
['http://udacity.com', 'http://egg.com', 'http://bread.com']
要了解正则表达式的含义,请查看以下内容:
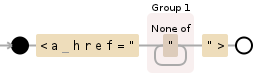
基本上,您可以看到它查找(感谢findall)并捕获以<a href="开头并以"> - <a href="…">结尾的所有内容,并捕获所有内容之间(字面意思是,任何不是"的字符) - ([^"]+)。
显示这是多少改进,这是我为了好玩而做的一个小基准,超过1000000,并从print删除print_all_links函数:
>>> timeit.timeit(stmt=lambda: print_all_links(page), number=1000000)
6.7976109981536865
>>> import re
>>> r = re.compile(r'<a href="([^"]+)">')
>>> timeit.timeit(stmt=lambda: r.findall(page), number=1000000)
1.823470115661621
>>> 6.7976109981536865/1.823470115661621
3.7278433793729966
HTH; - )
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?